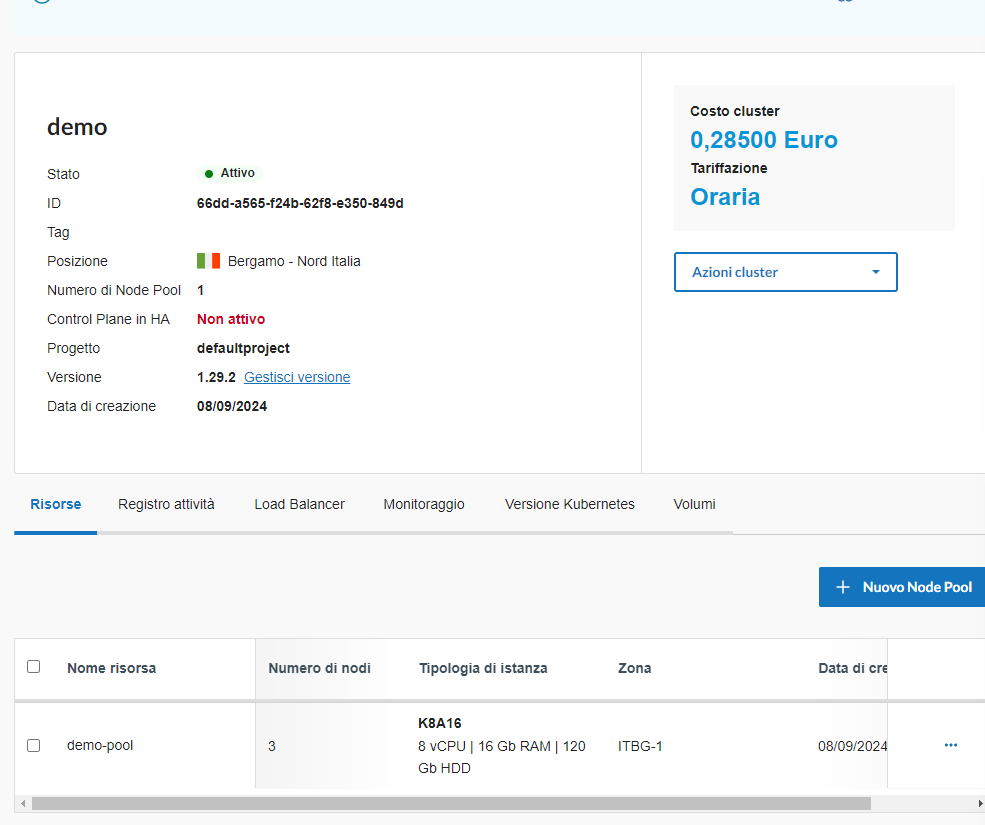
Deploy di un cluster Postgres in HA su Kubernetes

Come eseguire il deploy di un cluster Postgres in HA su Kubernetes: in questo articolo vediamo un esempio di utilizzo dell’operatore PostgreSQL per distribuire un cluster ad alta disponibilità in Kubernetes, sfruttando il servizio Aruba Managed Kubernetes.
Per creare il tuo cluster con un costo davvero contenuto (bastano meno di un euro al giorno!) puoi seguire questo articolo.
In questo esempio, utilizzerò l’operatore PostgreSQL di Zalando (sì, hai letto bene! Quella Zalando) per distribuire un cluster PostgreSQL con due nodi e un cluster Kubernetes creato tramite il servizio Aruba Managed Kubernetes con 8vCPU e 16 GB di RAM (ne bastano molti meno, come vedremo):
È possibile installare l’operatore Postgres utilizzando il chart Helm fornito, che consente di risparmiare passaggi manuali.
helm repo add postgres-operator-charts https://opensource.zalando.com/postgres-operator/charts/postgres-operator
helm install postgres-operator postgres-operator-charts/postgres-operator
L’avvio dell’operatore potrebbe richiedere alcuni secondi: controlla se il pod dell’operatore è in esecuzione prima di proseguire con la creazione delle risorse del cluster.
kubectl get pod -l app.kubernetes.io/name=postgres-operator
Se il pod dell’operatore è in esecuzione, possiamo proseguire e creare il cluster usando la risorsa custom postgresql fornita dall’operatore. All’interno del repository ufficiale ci sono diversi esempi di cluster, come una completa di ServiceMonitor o una versione minimale, che andremo ad utilizzare per il nostro test:
apiVersion: "acid.zalan.do/v1"
kind: postgresql
metadata:
name: acid-minimal-cluster
spec:
teamId: "acid"
volume:
size: 1Gi
numberOfInstances: 2
users:
zalando:
- superuser
- createdb
foo_user: []
databases:
foo: zalando
preparedDatabases:
bar: {}
postgresql:
version: "16"
Il file YAML riportato definisce un manifest minimo per la creazione di un’istanza di PostgreSQL utilizzando l’operatore creato da Zalando.
Esso specifica le configurazioni necessarie per il deployment di un database PostgreSQL, inclusi i parametri per il numero di repliche, le risorse richieste e le impostazioni di storage. In particolare, il manifest include:
metadata: informazioni identificative come il nome e il namespace dell’istanza.- spec: dettagli sulla configurazione del database, come il numero di repliche e le
risorsedi CPU e memoria. volume: configurazioni per il volume persistente, assicurando che i dati siano conservati anche dopo il riavvio dell’istanza.
Verranno creati due utenti: zalando e foo_user, in cui il primo avrà i privilegi sul cluster, mentre il secondo sarà un utente normale.
Il comando per eseguire il deploy all’interno di un namespace chiamato postgres è il seguente:
kubectl create -f minimal-postgres-manifest.yaml -n postgres
Dopo che il cluster è stato creato, l’operatore creerà risorse di servizio ed endpoint e uno StatefulSet che avvia nuovi Pod secondo il numero di istanze specificato nel manifest (2, nel nostro caso).
Tutte le risorse seguiranno la naming convention del cluster: i pod del database possono infatti essere identificati dal suffisso del loro numero, a partire da -0.
Per quanto riguarda i Service e gli endpoint, ce ne sarà uno per il pod master e un altro per tutte le repliche (suffisso -repl). Per controllare che i Pod siano correttamente in esecuzione, possiamo eseguire il comando seguente sfruttando le label assegnate ai Pod con il selector application il cui valore è spilo (nome dell’immagine dell’operator di Zalando):
kubectl get pods -l application=spilo -L spilo-role -n postgres
>>>
NAME READY STATUS RESTARTS AGE SPILO-ROLE
acid-minimal-cluster-0 1/1 Running 0 99s master
acid-minimal-cluster-1 1/1 Running 0 72s replica
A questo punto, con un port-forward su uno dei pod del database (ad esempio il master) è possibile connettersi al database PostgreSQL dal proprio host.
Per farlo, eseguiamo i seguenti comando, con i quali recuperiamo il nome del Pod che esegue il master del database e procediamo al port-forwarding verso la porta 6432 locale:
export PGMASTER=$(kubectl get pods -o jsonpath={.items..metadata.name} -l application=spilo,cluster-name=acid-minimal-cluster,spilo-role=master -n postgres) # specificare il namespace dove il cluster è stato creato
kubectl port-forward $PGMASTER 6432:5432 -n postgres
Siamo finalmente pronti per iniziare ad utilizzare il database… Ah no! Manca un pezzo: ci serve la password per accedere al cluster.
export PGPASSWORD=$(kubectl get secret postgres.acid-minimal-cluster.credentials.postgresql.acid.zalan.do -o 'jsonpath={.data.password}' | base64 -d)
export PGSSLMODE=require
psql -U postgres -h localhost -p 6432
Siamo al punto in cui possiamo aprire il nostro client preferito (pgAdmin, TablePlus o usare anche il terminale stesso con psql) per testare la connessione: usiamo l’utente postgres e la password recuperata in precedenza per collegarci.
Connessione al cluster Postgres tramite pgAdmin4
Se volessi usare psql, esegui i seguenti comandi, tenendo conto che poiché le connessioni non crittografate vengono rifiutate per impostazione predefinita, imposta la modalità SSL su require.
export PGSSLMODE=require
psql -U postgres -h localhost -p 6432
E se volessimo testare l’alta affidabilità del cluster?
Eliminiamo il pod nel cluster K8S che è master e verifichiamo che la procedura di failover funzioni.
kubectl delete pod acid-minimal-cluster-0 -n postgres
>>>
pod "acid-minimal-cluster-0" deleted
Dopo l’eliminazione, esaminiamo i pod: il Pod acid-minimal-cluster-0 è stato ricreato ed è diventato secondario, mentre il Pod acid-minimal-cluster-1 è diventato il nuovo leader.
kubectl get pods -n postgres -l application=spilo -L spilo-role
>>>
NAME READY STATUS RESTARTS AGE SPILO-ROLE
acid-minimal-cluster-0 1/1 Running 0 33s replica
acid-minimal-cluster-1 1/1 Running 0 13m master
Dopo il failover, colleghiamoci a PostgreSQL e assicuriamoci che i dati popolati in precedenza siano persistenti.
Facciamo anche caso ad una cosa: i Pod sono stati deployati ognuno su un nodo diverso del cluster, come visibile di seguito:
kubectl get pods -o wide -n postgres -l application=spilo -L spilo-role
>>>
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES SPILO-ROLE
acid-minimal-cluster-0 1/1 Running 0 40m 192.168.144.133 66dda565f24b62f8e350849d--osmt-demo-pool--v1292-67x2w <none> <none> replica
acid-minimal-cluster-1 1/1 Running 0 54m 192.168.175.197 66dda565f24b62f8e350849d--osmt-demo-pool--v1292-z4qqj <none> <none> master
Se andassimo a modificare il numero di repliche presenti nell’istanza della CRD postgres, vedremmo che la terza istanza del cluster Postgres verrebbe eseguita sul terzo nodo a disposizione:
kubectl edit statefulset acid-minimal-cluster -n postgres
>>
statefulset.apps/acid-minimal-cluster edited
PS C:\Users\serena.sensini> kubectl get pods -o wide -n postgres -l application=spilo -L spilo-role
>>>
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES SPILO-ROLE
acid-minimal-cluster-0 1/1 Running 0 42m 192.168.144.133 66dda565f24b62f8e350849d--osmt-demo-pool--v1292-67x2w <none> <none> replica
acid-minimal-cluster-1 1/1 Running 0 55m 192.168.175.197 66dda565f24b62f8e350849d--osmt-demo-pool--v1292-z4qqj <none> <none> master
acid-minimal-cluster-2 1/1 Running 0 3s <none> 66dda565f24b62f8e350849d--osmt-demo-pool--v1292-n4s9t <none> <none>
La cosa interessante è la possibilità di visualizzare anche i consumi delle risorse di questo cluster: andando sulla dashboard Aruba, nella sezione di Monitoraggio del cluster Kubernetes, vediamo che i dati relativi a CPU, memoria e traffico di rete:
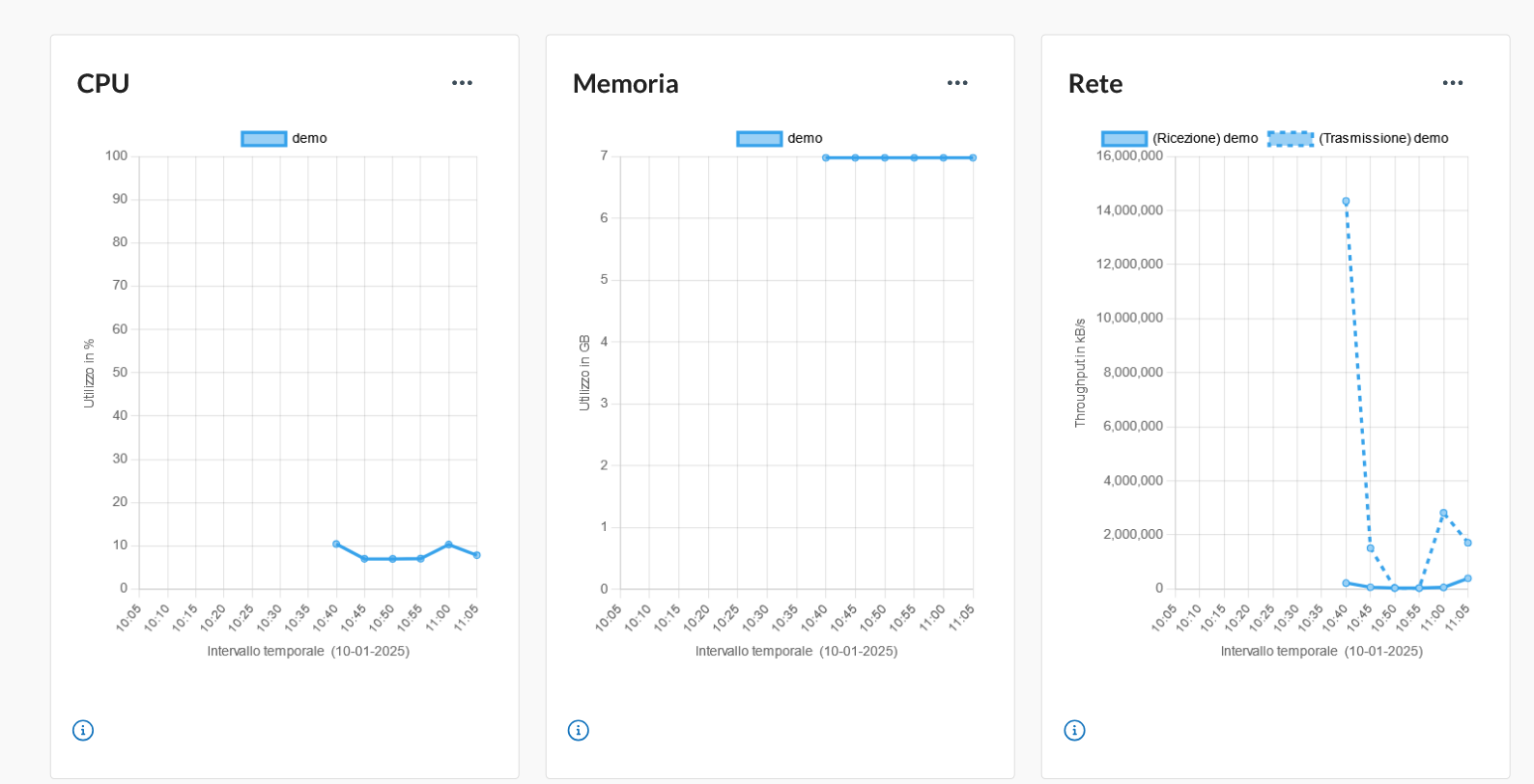
Hai visto? Avere un cluster Postgres in HA su Kubernetes è estremamente facile grazie all’operatore creato da Zalando e sfruttando il servizio per la gestione di cluster Kubernetes managed di Aruba!



