Relazionale o non relazionale: questo è il problema

All’interno del mondo dei database, esiste una distinzione netta: i database relazionali, chiamati anche database SQL, e tutti gli altri, chiamati non relazionali o NoSQL. Quali sono le differenze, e quando viene adottato l’uno o l’altro?
Database, o DBMS?
Ma cos’è un database? È una raccolta casuale di informazioni, tutte messe insieme? Al contrario: i database sono organizzati, hanno una struttura propria e tutti i dati che memorizzano si adattano a quella struttura. Più specificamente,
un database è un sistema elettronico che consente di archiviare i dati, accedervi facilmente, manipolarli e aggiornarli secondo esigenza.
In questo contesto, intendiamo quindi un database come una banca dati organizzata e accedibile tramite un sistema software che ne consente la consultazione dei dati. Questo è anche chiamato DBMS, ossia database management system.
SQL vs NoSQL
Avendo chiara questa definizione, vediamo quali sono le due grandi famiglie di database presenti.
Sapendo che SQL è un linguaggio di programmazione, possiamo dire anche che questo consente agli utenti che usano database relazionali di lavorare con schemi predefiniti e gestire dati strutturati spesso in righe e tabelle.
D’altro canto, NoSQL sta per “Not Only SQL”, offre un approccio più flessibile a quello non relazionale, ideale per la gestione di dati non strutturati o dinamici. Man mano che le aziende si evolvono e i dati diventano sempre più diversificati, è importante comprendere le differenze fondamentali tra SQL e NoSQL.
Quando si sceglie un database, infatti, una delle decisioni più importanti è scegliere una struttura dati relazionale o non. Entrambi i sistemi offrono vantaggi unici e soddisfano esigenze diverse, rendendo la scelta tra loro fondamentale per una gestione ottimale dei dati.
Questo vuol dire anche che nella famiglia dei database NoSQL coesistono diversi sottogruppi, come i database a grafo, quelli gerarchici, a colonne o anche basati su documenti: mentre la famiglia dei database relazionali accomuna tutti quei sistemi che hanno come minimo comune denominatore SQL, questo gruppo racchiude moltissimi altri linguaggi, architetture e modalità di persistenza dei dati.
Credits to Expeed.com
Quale scegliere?
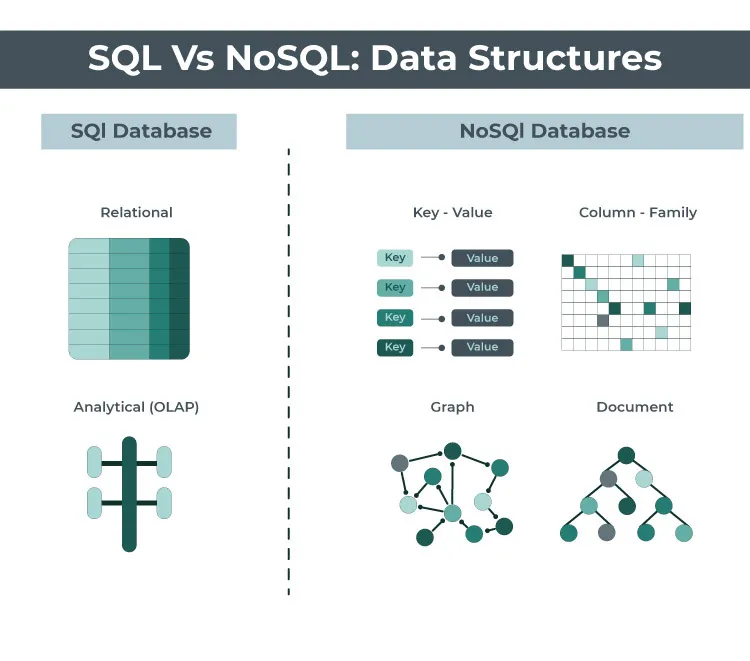
La più grande differenza tra i database SQL e NoSQL è la struttura dei dati. Come accennato in precedenza, i database SQL utilizzano una struttura basata su tabelle, mentre i database NoSQL possono utilizzare varie strutture dati.
Questa differenza è fondamentale perché influisce sul modo in cui i dati vengono archiviati e accessibili. In un database relazionale, i dati vengono generalmente archiviati in righe e colonne e ciò può rendere difficile l’archiviazione di tipi di dati complessi, come dati di sensori, post sui social media, documenti, contenuto di articoli o immagini. D’altra parte, i database NoSQL sono progettati per funzionare con strutture dati più flessibili.
Un’altra differenza fondamentale tra i database SQL e NoSQL sono i linguaggi di query. Come detto in precedenza, i database NoSQL utilizzano una varietà di linguaggi di query, tra cui MapReduce e Apache Hive.
Parliamo inoltre di indicizzazione, ossia il modo per ottimizzare le prestazioni di un database creando un indice che consente di recuperare rapidamente i dati. Sia i database SQL che NoSQL supportano l’indicizzazione, ma lo ottengono in modo diverso. In un database relazionale (SQL), gli indici vengono generalmente creati su colonne. In un database NoSQL è possibile creare indici su qualsiasi tipo di dati, inclusi documenti e chiavi.
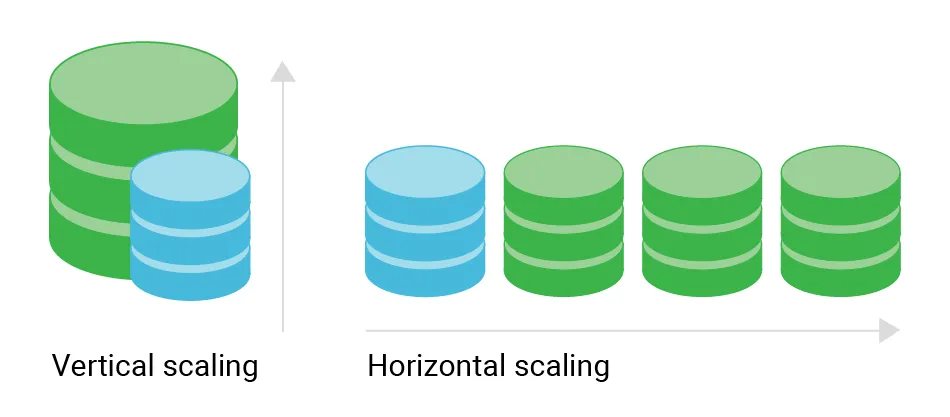
Un altro fattore chiave è la scalabilità, ovvero la capacità di un sistema di gestire l’aumento del carico senza degrado delle prestazioni. In un database relazionale, la scalabilità è verticale, ad esempio aggiungendo più server.
Nel caso di database NoSQL, questa viene generalmente raggiunta orizzontalmente, ad esempio aggiungendo più nodi al sistema.
Credits to scylladb.com
Queste caratteristiche fanno sì che, nel momento della scelta, sia necessario riflettere su questi aspetti e valutare in primo luogo al tipo di dato che si vuole rappresentare, l’importanza delle relazioni (se presenti) tra le informazioni e la relativa tipologia, oltre che le performance richieste e la necessità di scalare o meno.
Scelta non facile, ma che deve essere ben ponderata valutando ognuno di questi aspetti.
🔗 Leggi anche:

Articoli Correlati