Esplorando il Dockerfile

Finora abbiamo sempre parlato di Docker, ma senza entrare nel dettaglio in merito a cosa succede quando andiamo a farlo funzionare: oggi, esplorando il Dockerfile, cerchiamo di riprendere un po’ di concetti lasciati da parte e di chiarirne il funzionamento con alcuni esempi.
Introduzione
Il Dockerfile è alla base della creazione di immagini Docker: per chi ne ha una vaga idea, si tratta di un file di testo che contiene un elenco di comandi (o più genericamente istruzioni) e descrive il modo in cui un’immagine Docker viene costruita: un’analogia che mi piace spesso fare è quella di paragonare il Dockerfile ad una sorta di ricetta che contiene tutti gli ingredienti del nostro piatto. Una volta che abbiamo bisogno di preparare il nostro piatto, ci basta prendere la ricetta ed “avviarne” il procedimento, per creare il nostro container.
Vediamo però com’è formato, cosa produce e cosa c’è dietro le quinte...
Struttura di un Dockerfile
Un Dockerfile inizia sempre con un comando FROM che indica l’immagine di partenza che il container andrà ad utilizzare; infatti, i comandi successivi nel file vengono eseguiti all’interno dell’immagine di base che deve essere un’immagine valida.
Un esempio di Dockerfile di un’applicazione Angular è il seguente:
# Immagine di base FROM node:16.0.0
Cartella di lavoro
WORKDIR ‘/app’
Copia dell’elenco dipendenze
COPY package.json .
Installazione delle dipendenze
RUN npm install
Copia dell’applicazione
COPY . .
Porta in ascolto
EXPOSE 4200
Avvio dell’applicazione
CMD [“npm”, “start”]
(P.s.: se vuoi saperne di più, leggi questo articolo!)
In questo caso, l’immagine di base è quella di Ubuntu (indicata dalla riga con l’istruzione FROM), e poi vengono descritti i vari passaggi che richiede l’esecuzione dell’applicazione: copia delle dipendenze, installazione, e via dicendo. Ora che ho tutto pronto, cosa faccio?
Come funziona il contesto
Grazie al concetto di contesto, posso effettuare la build dell’immagine: eseguendo infatti il seguente comando all’interno della stessa cartella dove è stato salvato il Dockerfile, Docker costruisce il container finale seguendo passo passo le istruzioni che abbiamo inserito all’interno della nostra ricetta.
$ docker image build .
Una nota importante qui è che la build viene eseguita dal daemon Docker, quindi l’intero contesto (la cartella in cui si trova il Dockerfile e all’interno del quale andiamo ad eseguire il comando) viene trasferito al daemon. Dall’output del comando riportato in precedenza, questo è quanto viene mostrato:
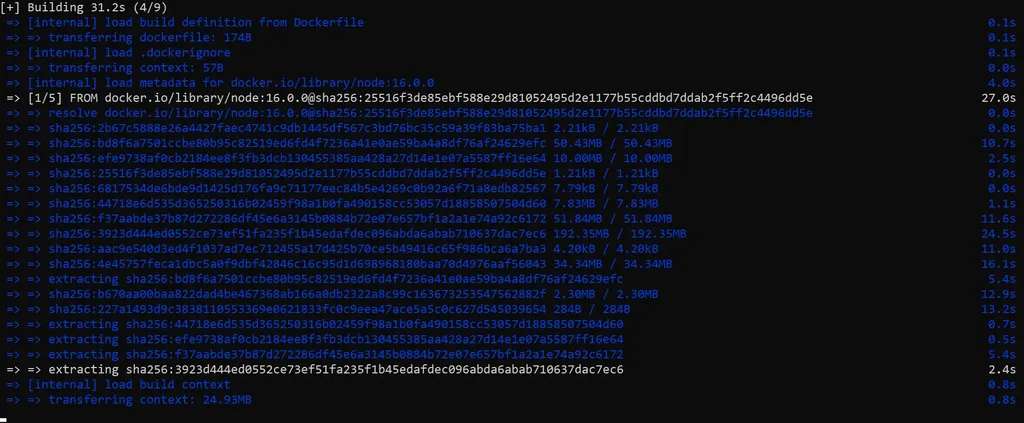 Dimensione del contesto trasferito
Dimensione del contesto trasferito
Come avrai notato, l’output indica anche quanti dati vengono trasferiti (25MB nell’esempio) grazie al contesto; questo perché l’applicazione dispone di diversi componenti e, come la maggior parte delle applicazioni in Angular, l’applicazione pesa diversi MB.
Pertanto, un avviso importante ai telespettatori: MAI utilizzare la directory root come contesto poiché fa sì che la build trasferisca l’intero contenuto del tuo disco rigido al daemon Docker.
No, non è uno scherzo: il path specificato come contesto definisce dove trovare i file per i riferimenti sul contesto da utilizzare nel processo di build del daemon Docker; ciò significa che vengono inviati tutti i file presenti nel contesto, non solo quelli elencati in un’eventuale istruzione ADD nel Dockerfile. Il trasferimento del contesto dalla macchina locale al daemon Docker è specificato proprio dalle righe “Transferring context” o “Sending build context”.
E i layers?
Abbiamo detto che il daemon Docker, quando crea la tua immagine, esegue passo passo quanto definito nel Dockerfile. In ogni passaggio viene generato un container intermedio e l’istruzione viene eseguita all’interno del container generato; una volta che l’istruzione ha esito positivo, il container viene memorizzato come una nuova immagine, come nuovo_layer_. Vuol dire che l’istruzione successiva ne costruirà un’altra nuova sopra quella precedente.
Diamo una rapida occhiata all’output completo della creazione del Dockerfile di esempio:
$ docker image build . [+] Building 94.8s (10/10) FINISHED => [internal] load build definition from Dockerfile 0.1s => => transferring dockerfile: 174B 0.0s => [internal] load .dockerignore 0.0s => => transferring context: 57B 0.0s => [internal] load metadata for docker.io/library/node:16.0.0 2.3s => [1/5] FROM docker.io/library/node:16.0.0@sha256:25516f3de85ebf588e29d81052495d2e1177b55cddbd7ddab2f5ff2c4496dd5e 0.3s => => resolve docker.io/library/node:16.0.0@sha256:25516f3de85ebf588e29d81052495d2e1177b55cddbd7ddab2f5ff2c4496dd5e 0.0s => => sha256:2b67c5888e26a4427faec4741c9db1445df567c3bd76bc35c59a39f83ba75ba1 2.21kB / 2.21kB 0.0s => => sha256:25516f3de85ebf588e29d81052495d2e1177b55cddbd7ddab2f5ff2c4496dd5e 1.21kB / 1.21kB 0.0s => => sha256:6817534de6bde9d1425d176fa9c71177eec84b5e4269c0b92a6f71a8edb82567 7.79kB / 7.79kB 0.0s => [internal] load build context 0.3s => => transferring context: 24.93MB 0.3s => [2/5] WORKDIR /app 0.1s => [3/5] COPY package.json . 0.0s => [4/5] RUN npm install 81.6s => [5/5] COPY . . 0.2s => exporting to image 10.2s => => exporting layers 10.2s => => writing image sha256:c4d6da5125d6ceee71148f84787fdabcfbb0a14b1eb7007240034b6ad1e24a25
Infatti un’immagine Docker è composta da diversi livelli, o_layers_: ogni container è un’immagine con un livello leggibile e scrivibile che viene posto sopra un gruppo di livelli di sola lettura. Questi livelli (chiamati anche immagini intermedie) vengono generati quando i comandi nel Dockerfile vengono eseguiti durante il processo di build dell’immagine Docker.
Come mostrato nell’output precedente, quando Docker crea il container a partire dal Dockerfile, ogni passaggio corrisponde a un comando eseguito nel Dockerfile e ogni livello è costituito dal file generato dall’esecuzione di quel comando. Insieme a ogni passaggio, il livello creato è elencato e rappresentato dal suo digest generato casualmente (ad esempio, il digest del livello per il passaggio 1 è 6817534de6bde9d1425d176fa9c71177eec84b5e4269c0b92a6f71a8edb82567).
In questo caso, ci sono 5 passaggi riportati nell’output perché ci sono 5 righe di istruzioni nel Dockerfile (escludendo i commenti, ovviamente). Dopo aver completato tutti i passaggi, l’immagine verrà visualizzata nell’output del comando seguente:
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE myimage 0.0.1 f6c0798a113c 5 minutes ago 1.5GB
E se volessimo vedere come è stata costruita la nostra immagine? Eseguiamo il comando docker history :
 History dell’immagine appena creata
History dell’immagine appena creata
Vediamo che nella colonna IMAGE ci sono due valori, ossia una stringa alfanumerica (che corrisponde ad un ID) e una serie di . Ognuna di queste righe riporta anche l’istruzione che ha generato quell’immagine e la dimensione… ma cosa rappresenta quel_missing_?
Sembra molto più complicato di quanto non sia: storicamente parlando (prima di Docker v1.10), ogni volta che veniva creato un nuovo layer come risultato di un’azione, Docker creava anche un’immagine corrispondente, identificata da un codice UUID a 256 bit generato casualmente, indicato come ID dell’immagine; storicamente si parlava infatti di immagini intermedie, senza tag “human-friendly”.
A partire da Docker 1.10, immagini e livelli non sono più sinonimi: invece, un’immagine fa riferimento direttamente a uno o più layer che alla fine contribuiscono al filesystem di un container.
Nella colonna IMAGE il termine significa proprio questo: quelle non sono immagini, ma livelli e sono parti costitutive dell’immagine.

Che diavolo, perché la colonna si chiama così?
In realtà, quando viene eseguito il commit di un layer durante la creazione di un’immagine, viene creata contemporaneamente un’immagine “intermedia” e, proprio come tutte le altre immagini, ha un elemento di configurazione che è rappresentato da un elenco dei digest che devono essere incorporati come parte dell’immagine, e il suo ID contiene un hash dell’oggetto di configurazione. Le immagini intermedie non sono contrassegnate con un nome, ma hanno una chiave “Parent”, che contiene l’ID dell’immagine principale.
Quindi, in realtà, quando costruisci localmente, quei layer sono immagini (proprio come erano una volta, anche quando li andavamo ad estrarre da qualche altra parte nella versione precedente descritta) e sono usati per facilitare il processo di cache (parte che rende veloci le build se hai già costruito quel livello).
Quindi la risposta è … a volte sono immagini (tecnicamente), a volte sono livelli (e quindi rappresentati in quella colonna come ).
A tutta cache!
Se andassimo ad eseguire nuovamente il comando di build, vedremmo che i tempi sono notevolmente diminuiti:
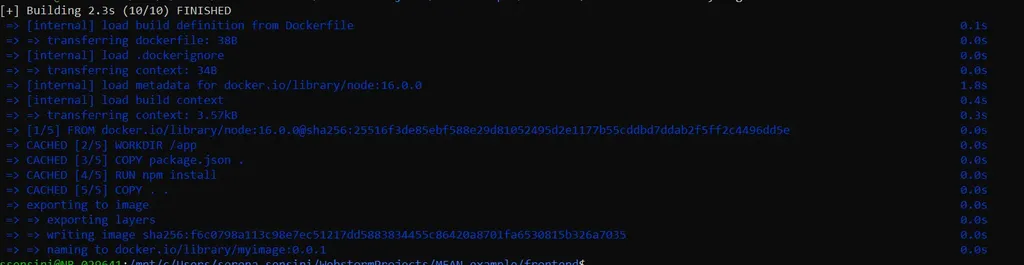 Esempio di uso della cache
Esempio di uso della cache
Noterai “CACHED” in ogni passaggio, il che indica che il daemon Docker ha utilizzato la cache direttamente per generare l’immagine intermedia invece di ricostruirla.
La cache viene utilizzata quando le istruzioni nel Dockerfile sono uguali o invariate rispetto alla versione precedente, ed è molto utile quando l’immagine di cui dobbiamo effettuare la build è corposa.
Ad ogni occorrenza di un comando RUN nel Dockerfile, Docker creerà e committerà un nuovo layer nell’immagine, che è solo un insieme di directory strettamente accoppiate piene di varie strutture di file che comprendono un’immagine Docker. In un’installazione predefinita, questi si trovano in /var/lib/docker (questo non vale per Docker Desktop).
Durante una nuova build, tutte queste strutture devono essere create e scritte su disco: è qui che Docker memorizza le immagini di base. Una volta creato, il container (e i successivi nuovi) verrà archiviato nella cartella in questa stessa area.
Cosa rende importante la cache? Se gli oggetti sul filesystem che Docker sta per produrre rimangono invariati tra le build, riutilizzare la cache di una build precedente sull’host è un grande risparmio di tempo -basti pensare che la differenza in termini di tempo dei due processi di_build_ precedenti è di un minuto e mezzo contro 2 secondi quando ci si avvale della cache-.
Tuttavia, quella cache viene utilizzata in modo piuttosto aggressivo e può causare problemi quando si desidera che l’output aggiornato di un comando RUN venga inserito nel nuovo container . Allo stato attuale, a meno che il comando RUN non cambi (e quindi invalidi la cache su host di Docker), Docker riutilizzerà i risultati precedenti dalla cache; ciò è chiaramente svantaggioso quando il comando RUN è un checkout del codice sorgente, come ad esempio avviene per il clone di un progetto Git.
Fortunatamente, ci sono un paio di modi per aggirare questo problema: in primis, è possibile eseguire una build Docker con l’opzione “-no-cache”, che ignora completamente tutta la cache a disposizione e quindi per ogni processo di build sarà necessario tanto tempo quanto la prima.
Questo approccio è chiaramente binario: o usi la cache o no, e quindi rappresenta un approccio molto drastico.
Per ottenere lo stesso risultato, ma sfruttando comunque la cache, si potrebbero inserire delle operazioni di controllo del codice sorgente nell’ultima istruzione di RUN nel Dockerfile, assicurandoci che venga eseguita ogni volta: basta racchiudere la build in un altro script che genera un mini-script con numero univoco per l’operazione di clonazione.
Questo passaggio inserirà l’invocazione di quello script nel Dockerfile che viene generato al volo appena prima del processo di build, di modo tale che per l’operazione che deve essere eseguita ogni volta - in questo caso, il clone del progetto - la sua istruzione RUN sia davvero unica.
Risorse utili
- Manuale Docker in italiano
- Docker cheatsheet
- Dockerfile cheatsheet
- Guida sulla differenza immagine vs. layer
- Come installare Docker (e Docker Compose)



