K8S in produzione: best practices

Sono sempre più frequenti le richieste di adozione di tecnologie appartenenti al mondo OCI: container a destra, pod a sinistra…
Installare e testare Docker o Podman localmente è semplice, ma cosa succede quando dobbiamo andare in produzione e abbiamo a che fare con Kubernetes?
Definiamo quindi una checklist di verifiche da completare quando il nostro ambiente di produzione sta per entrare in funzione e vediamo quali sono le best practices per portare K8S in produzione!
Docker vs. Kubernetes
Utilizzare Kubernetes dà l’opportunità di usare gli stessi strumenti che oggi usano le più grandi aziende nel mondo, le quali distribuiscono applicazioni basate su container.
Perché questa scelta? Tengono fede a tutte le promesse fatte in materia di resilienza dell’architettura o del servizio, della robustezza e della sicurezza dell’applicazione; si tratta di comuni best practices da applicare sempre.

Sapevi da dove nasce il nome di Kubernetes?
Kubernetes, di base, è un sistema per l’esecuzione e il coordinamento di applicazioni containerizzate in un cluster di macchine. È una piattaforma progettata per gestire completamente il ciclo di vita di applicazioni basati su container fornendo degli strumento per gestirne scalabilità e alta disponibilità.
Grazie ad una serie di funzionalità, è possibile ridimensionare i servizi, eseguire aggiornamenti continui e trasferire il traffico tra diverse versioni delle applicazioni per testare funzionalità o rollback di distribuzioni problematiche.
La creazione di un singolo container da eseguire per uso personale non richiede molte risorse o qualche tipo di pianificazione; sicuramente avrete visto quanto sia semplice avviare un servizio Docker in locale ed eseguire tramite pochi comandi l’avvio di un container per renderlo disponibile.
La creazione di container su cui però fare affidamento per fornire ad un cliente servizi più complessi in modo sicuro, affidabile, aggiornabile e scalabile comporta una nuova serie di sfide.
Ad esempio, distribuire un’applicazione che includa più componenti (es. un server Web, un database e un server di autenticazione), piuttosto che configurare il sistema per avere delle repliche in caso di arresto anomalo di uno di questi, è fondamentale in un sistema su larga scala.
Docker vs. Kubernetes
Architettura
Per capire come Kubernetes è in grado di fornire queste funzionalità, è utile avere un’idea di come è progettato e organizzato ad alto livello.
Può essere visualizzato come un sistema integrato in livelli, in cui ogni livello superiore sottrae la complessità riscontrata nei livelli inferiori.
Quello sottostante è uno schema abbastanza completo del funzionamento di Kubernetes: alla sua base, Kubernetes riunisce singole macchine fisiche o virtuali in un cluster utilizzando una rete condivisa per comunicare tra ciascun server.
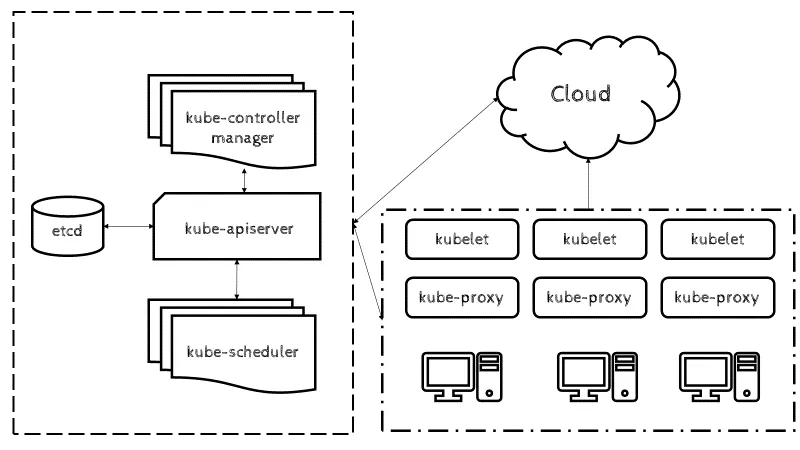 Rappresentazione dei componenti dell’architettura K8S
Rappresentazione dei componenti dell’architettura K8S
Questo cluster è la piattaforma fisica in cui sono configurati tutti i componenti, le capacità e i carichi di lavoro di Kubernetes.
A ciascuna macchina del cluster viene assegnato un ruolo all’interno dell’ecosistema Kubernetes: una macchina (o un piccolo gruppo in distribuzioni altamente disponibili) funziona come nodo principale, ed è quello che in figura si trova sulla sinistra, definito come “control plane”.
Questo nodo funge da gateway e oltre che da “cervello” del cluster, esponendo una serie di API per utenti e client e verificando l’integrità degli altri server, oppure decidendo il modo migliore per suddividere e assegnare il lavoro e orchestrando la comunicazione tra altri componenti.
Il nodo principale funge da punto di contatto primario con il cluster ed è responsabile della maggior parte della logica centralizzata fornita da Kubernetes.
Le altre macchine nel cluster sono designate come nodi (spesso chiamati minions) e sono i server responsabili dell’accettazione e dell’esecuzione dei carichi di lavoro utilizzando risorse locali ed esterne.
Per aiutare nelle attività di isolamento, gestione e flessibilità, Kubernetes esegue applicazioni e servizi in container, quindi ogni nodo deve essere dotato di un’istanza del container.
Il nodo riceve le istruzioni di lavoro dal server principale e crea o distrugge i container di conseguenza, configurando le regole di rete per instradare e inoltrare il traffico in modo appropriato.

Semplificazione di un cluster K8S in produzione

Elenco degli oggetti principali del mondo K8S (e non solo!)

Esempio di pod con tre container
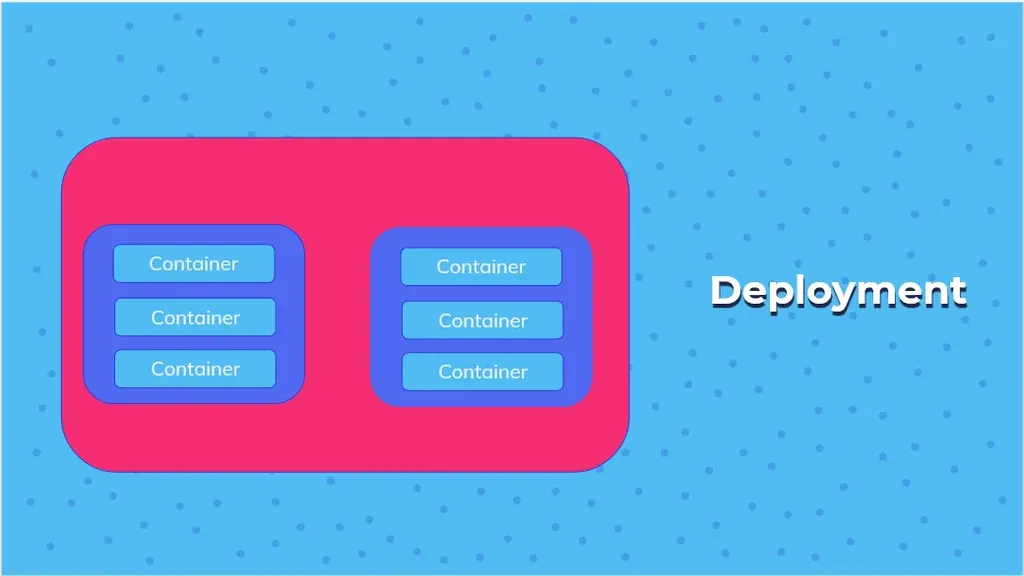
Esempio di Deployment con due pod in replica
Checklist
Dopo questa (non) brevissima introduzione al funzionamento di Kubernetes, vediamo adesso una lista di controlli che costituiscono delle vere e proprie best practices e che sono fondamentali quando abbiamo a che fare con un ambiente di produzione (ma anche qualche stage prima!).
Healthcheck
Kubernetes offre due meccanismi per tenere traccia del ciclo di vita dei container dei pod: readiness probe e liveness probe.
La prima determina se un container è pronto a ricevere delle richieste e quindi del traffico in ingresso, mentre la seconda determina se l’oggetto è ancora in esecuzione o meno.
Grazie a queste “prove”, kubelet può decidere se instradare il traffico o se riavviare il pod.
Attenzione però: non esiste un valore predefinito per definire l’esito positivo o negativo di questi test. Piuttosto, è buona pratica definire una convenzione rispetto alle verifiche che vengono effettuate.
Se questi controlli non vengono configurati, kubelet presuppone che la nostra applicazione sia stata avviata correttamente e sia pronta a ricevere traffico non appena viene avviato il contenitore.
Vediamo un caso d’uso: consideriamo il seguente scenario, dove c’è un’app con interfaccia grafica che dipende da un’API che costituisce il back-end.
Se l’API è instabile (ad esempio, di tanto in tanto non è disponibile a causa di un bug), la readiness probe del back-end fallisce e anche la liveness del front-end; in questo caso, un errore all’interno di una dipendenza tra due componenti può propagarsi.
In questo senso, può essere l’ideale testare le due componenti e fornire un esito positivo solo quando entrambe le verifiche vanno a buon fine!
Gestione delle risorse
Spesso quando si ha a che fare con infrastrutture che lavorano su cloud, si pensa ad un pool infinito di risorse, ma difficilmente è così. Le risorse costano e i costi vanno tenuti in considerazione, impostando dei limiti di memoria e CPUper tutti i container.
I limiti delle risorse vengono utilizzati per vincolare la quantità di CPU e memoria che i container possono utilizzare e vengono impostati utilizzando la proprietà delle risorse di un container, e non solo.
Un numero illimitato di pod, in caso di utilizzo massivo, può portare a un impegno eccessivo delle risorse e a potenziali arresti anomali del nodo (e del kubelet).
Tags
Le labels (o etichette) sono un meccanismo super utile che è possibile utilizzare per organizzare gli oggetti Kubernetes.
Un’etichetta rappresenta una coppia chiave-valore senza alcun significato predefinito, quindi è possibile adattarla alle esigenze dettate dall’infrastruttura.
Queste possono essere applicate a tutte le risorse presenti nel cluster, ed è possibile utilizzarle per classificare le risorse in base a scopo, proprietario, ambiente o altri criteri.
Di seguito, riportiamo alcuni esempi utili, dove vengono utilizzate informazioni come il nome dell’applicazione (label con chiave name), oppure la versione (label con chiave version), a quale componente dell’infrastruttura ci si riferisce (ad esempio component).
Puoi taggare i tuoi Pod con:
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment
labels:
app.kubernetes.io/name: user-api
app.kubernetes.io/instance: user-api-1234
app.kubernetes.io/version: "1.0.1"
app.kubernetes.io/component: api
O ancora proprietario, utilizzato per identificare chi è responsabile della risorsa (tag pari a owner), oppure il nome del progetto (tag uguale a project) o anche la business-unit di riferimento (ossia business-unit).
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment
labels:
owner: my-team
project: app-project
business-unit: "12345a"
Logging
I log prodotti dalle applicazioni possono aiutarci a capire cosa sta succedendo all’interno dei singoli servizi e sono fondamentali per monitorare le attività o per effettuare del debug.
Generalmente, esistono due strategie di logging: passiva e attiva. Le applicazioni che utilizzano la gestione dei log passivi non sono a conoscenza dell’infrastruttura di logging e registrano i messaggi su output standard.
Questa best practice fa parte del metodo dell’app a dodici fattori.
Per quanto riguarda l’approccio attivo, l’applicazione stessa invia i dati a delle apposite applicazioni di gestione dei log, oppure li salva direttamente in un database.
Questo tuttavia è considerato l’approccio peggiore!
Scalabilità automatica
L’Horizontal Pod Autoscaler (abbreviato in HPA) è una funzionalità Kubernetes che permette di monitorare le applicazioni e aggiungere o rimuovere automaticamente repliche del pod in base all’utilizzo corrente delle risorse.
La configurazione dell’HPA consente alla soluzione di rimanere disponibile e reattiva in qualsiasi condizione di traffico, inclusi picchi imprevisti o eventuali guasti.
L’HPA può monitorare sia le metriche che fanno riferimento alle risorse integrate (CPU e l’utilizzo della memoria dei tuoi pod) sia sfruttando delle metriche personalizzate.
Nel caso delle metriche personalizzate, sei anche responsabile della raccolta e dell’esposizione di queste metriche, cosa che puoi fare, ad esempio, con Prometheus e Prometheus Adapter.
Gestione dell’accesso
Questo step si può riassumere in pochi, ma semplici punti:
- Applicare il principio del privilegio minimo, e quindi concedere agli utenti solo le autorizzazioni necessarie
- Adeguare continuamente la strategia RBAC, in quanto questa non è autosufficiente, ma è necessario adottare un approccio volto alla convalida continua della policy RBAC adottata.
- Definizione di un set di ruoli, che saranno poi assegnati e utilizzati adeguatamente, per non aumentare il rischio e la superficie di attacco.
Tips
Esternalizzare tutta la configurazione è molto importante, se si vuol rendere facilmente gestibile l’ambiente.
Questo tipo di approccio ha diversi vantaggi, tra il cui il fatto che, utilizzando oggetti come ConfigMap e Secret, la modifica della configurazione non richiede la ricompilazione dell’applicazione.
In Kubernetes, la configurazione può essere salvata in oggetti come le ConfigMaps, che può quindi essere montata in container tramite dei volumi dove queste informazioni vengono passate come variabili di ambiente.
Attenzione: è importante montare i Secrets come volumi, e non come variabili di ambiente, per evitare che i relativi valori vengano visualizzati nel comando utilizzato per avviare il container, il quale potrebbe essere analizzato da utenti che non dovrebbero averne l’accesso!
Risorse utili
- Docker - per cominciare bene con Docker e Kubernetes
- Kubernetes - Guida per gestire e orchestrare i container



