Observability e monitoring: come cambia il debugging nei sistemi distribuiti

Se hai mai passato ore a cercare la causa di un rallentamento in produzione sfogliando migliaia di righe di log, sai già di cosa parlo. Il servizio è lento, gli utenti si lamentano, e tu sei lì a fare grep su file enormi sperando di trovare l’ago nel pagliaio.
I log da soli non raccontano più tutta la storia. E no, aggiungerne altri non risolve il problema, lo peggiora.
Qui entra in gioco l’observability: un approccio che cambia il modo in cui capiamo cosa succede nei nostri sistemi.
Cos’è l’observability
L’observability è la capacità di capire lo stato interno di un sistema osservando i suoi output. Non è un tool, non è un prodotto: è un approccio.
💡 Curiosità: il termine viene dalla teoria dei controlli degli anni ‘60, non dal mondo IT. Un sistema è “osservabile” se puoi ricostruire il suo stato interno dalle sue uscite.
In pratica, significa raccogliere e correlare tre tipi di dati, i così detti tre pilastri:
Metriche: numeri aggregati nel tempo. CPU al 90%, latenza media 200ms, 50 richieste al secondo. Ti dicono che qualcosa sta succedendo.
Log: eventi testuali con timestamp. “Utente X ha fatto login”, “Errore connessione al database”. Ti dicono cosa è successo.
Trace: il percorso di una singola richiesta attraverso tutti i servizi. Ti dicono dove e perché è successo.
Perché servono tutti e tre
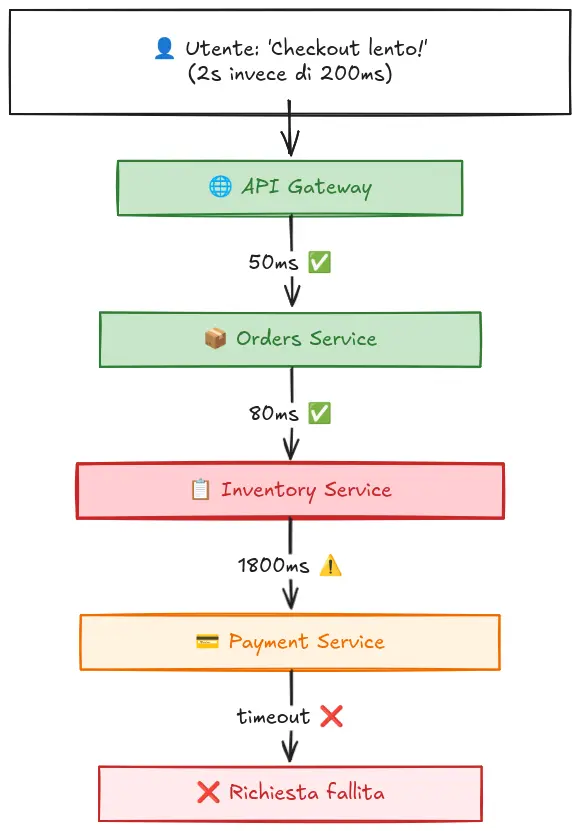
Immagina questo scenario: il tuo e-commerce ha un picco di latenza. Le metriche ti mostrano che il tempo di risposta medio è salito da 200ms a 2 secondi. Ok, c’è un problema. Ma dove?
Vai sui log. Trovi migliaia di righe, alcune con errori di timeout verso un servizio di pagamento. Ma è la causa o una conseguenza?
Qui le trace fanno la differenza. Prendi una singola richiesta lenta e vedi esattamente il suo percorso: API gateway → servizio ordini → servizio inventario → servizio pagamento. E scopri che il servizio inventario impiega 1.8 secondi per rispondere, causando timeout a cascata.
Senza le trace, avresti dato la colpa al servizio pagamento. Con le trace, trovi il vero colpevole in minuti invece che in ore.
Questo è il punto: i tre pilastri non sono alternativi, sono complementari. Le metriche ti avvisano, i log ti danno contesto, le trace ti guidano alla causa.
Observability vs Monitoring: qual è la differenza?
Spesso i due termini vengono usati come sinonimi, ma non lo sono.
Il monitoring è reattivo: definisci in anticipo cosa controllare, imposti soglie, e ricevi alert quando qualcosa le supera. Funziona bene per problemi noti, se sai che la CPU sopra il 90% è un problema, lo monitori.
L’observability è esplorativa: non devi sapere in anticipo cosa cercare. Raccogli dati ricchi e correlati che ti permettono di investigare problemi che non avevi previsto.
In pratica: il monitoring ti dice “c’è un problema”, l’observability ti aiuta a capire “perché c’è un problema” — anche quando è la prima volta che lo vedi.
Da dove iniziare
Se parti da zero, il consiglio è di non costruire tutto da solo. OpenTelemetry è diventato lo standard de facto per l’instrumentazione: è open source, vendor-neutral, e supportato da praticamente tutti i tool di observability.
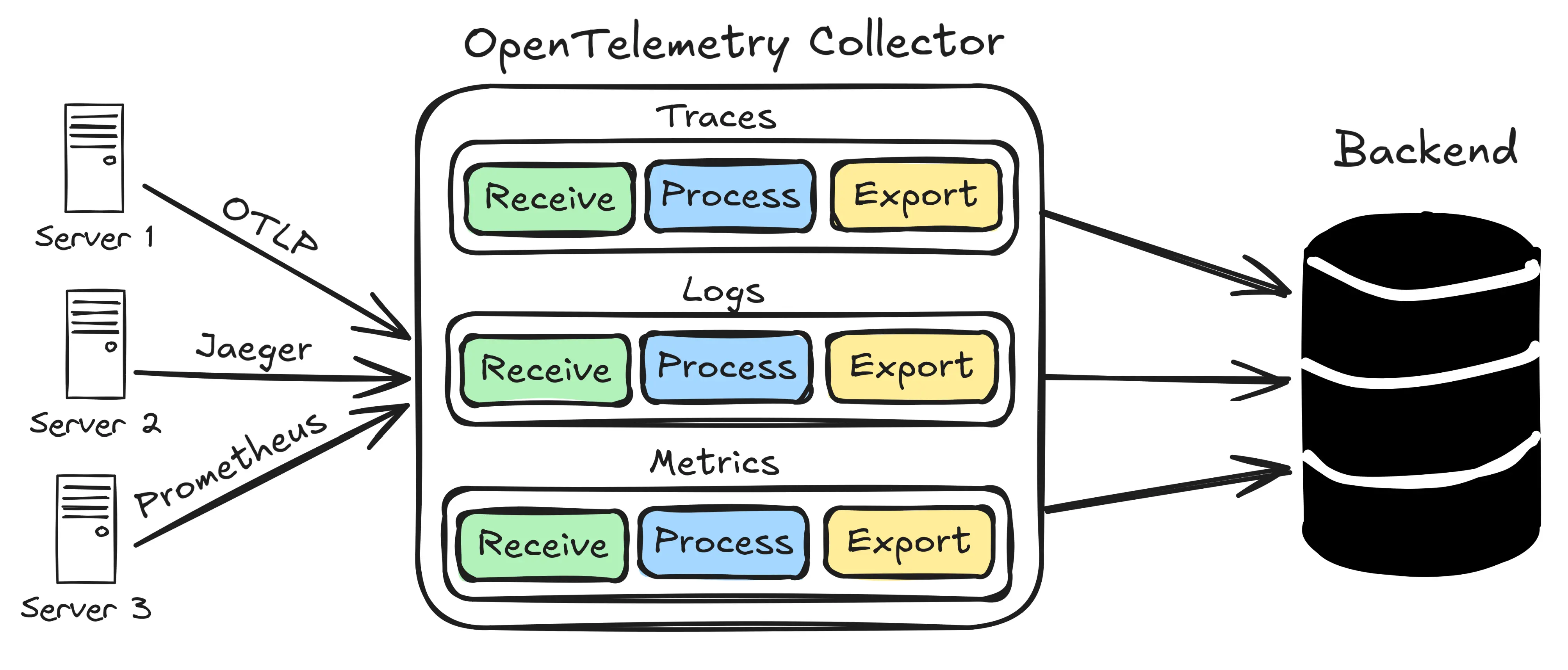
Oltre a librerie per instrumentare il codice, OpenTelemetry definisce un Collector: un componente che riceve, elabora e inoltra a gestori specifici i dati di telemetria. Funziona come una pipeline configurabile: puoi filtrare, arricchire, campionare e trasformare metriche, log e trace prima di inviarli al backend di visualizzazione.
I primi passi concreti:
Scegli uno stack di visualizzazione. Per iniziare senza costi: Grafana (metriche e dashboard), Loki (log), e Jaeger o Tempo (trace). Se preferisci un’opzione gestita, Datadog, New Relic e Elastic offrono tutto integrato.
Instrumenta un servizio. OpenTelemetry offre auto-instrumentation per i framework più comuni. In molti casi basta aggiungere una dipendenza e qualche riga di configurazione per avere trace automatiche delle chiamate HTTP e database.
Correla i dati. Il vero valore emerge quando trace, log e metriche condividono un identificatore comune (trace ID). Così puoi saltare da un alert su una metrica al log specifico alla trace completa con un click.
Non serve instrumentare tutto subito. Parti dal servizio che ti dà più problemi, impara il flusso, poi estendi.
Errori da evitare
Un paio di trappole comuni quando si inizia:
Instrumentare tutto subito. Genera rumore e costi. Meglio partire dal percorso critico (es. checkout, login) e espandere gradualmente.
Ignorare il campionamento. In produzione con alto traffico, tracciare il 100% delle richieste è insostenibile. OpenTelemetry supporta strategie di sampling intelligenti — usale.
Non correlare i dati. Avere metriche in Prometheus, log in Elasticsearch e trace in Jaeger senza un trace ID comune vanifica metà del valore. La correlazione non è un nice-to-have.
Conclusioni
L’observability non è “logging avanzato” ma un cambio di mentalità. Invece di chiederti “cosa loggo?”, ti chiedi “quali domande dovrò fare quando qualcosa si rompe?”.
Se i tuoi sistemi sono distribuiti, se fai deploy frequenti, se vuoi passare meno tempo a debuggare e più tempo a costruire: vale la pena investire su questo approccio.
Risorse utili:
- OpenTelemetry Documentation — il punto di partenza ufficiale
- Grafana Stack — Grafana + Loki + Tempo, tutto open source
- Distributed Systems Observability — ebook gratuito O’Reilly per approfondire



