Pod orfani: il caso Netflix

Kubernetes fornisce una piattaforma per automatizzare il rilascio e le operazioni legate al ciclo di vita dei container definendo le risorse come oggetti “gestiti”, o managed.
Alcune di queste risorse possono essere gestite automaticamente da altri elementi, mentre ad altre è possibile fare riferimento tramite campi di metadata all’interno della definizione dell’oggetto stesso.
Col tempo, alcuni di questi oggetti potrebbero arrestarsi e non verranno più utilizzati, cadendo in uno stato di limbo o diventando quelle che chiamiamo risorse orfane.
Orphaned pods, letteralmente “pod orfani”. Cosa sono?
In altre parole, sono Pod che non sono mai riusciti a “terminare” correttamente e che dovrebbero essere eliminati.
[root@k8s pods]# journalctl -fu kubelet
-- Logs begin at 二 2019-05-21 08:52:08 CST. --
May 21 14:48:48 k8s-node4 kubelet[2493]: E0521 14:48:48.748460 2493 kubelet_volumes.go:140] Orphaned pod "d29f26dc-77bb-11e9-971b-0050568417a2" found, but volume paths are still present on disk : There were a total of 1 errors similar to this. Turn up verbosity to see them.
Per fortuna, c’è un garbage collector (abbreviato in GC) che aiuta a fare pulizia.
Il ruolo del GC Kubernetes è infatti quello di eliminare gli oggetti che una volta avevano un proprietario, ma che ora non ne hanno più uno.
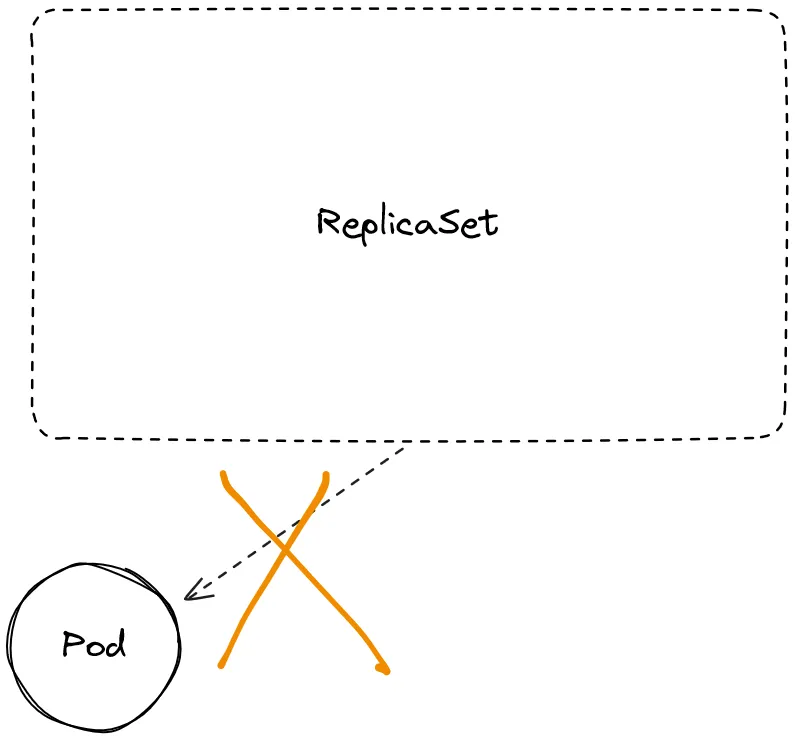
Ad esempio, un oggetto ReplicaSet è il proprietario di un set di pod. Gli oggetti posseduti sono chiamati dipendenti dell’oggetto proprietario.
Nei linguaggi di programmazione tradizionali, i principi di base della garbage collection consistono nel trovare oggetti dati in un programma a cui non sarà possibile accedere in futuro e nel recuperare le risorse utilizzate da tali oggetti.
In Kubernetes, il GC funziona in modo leggermente diverso: gli oggetti dipendenti hanno un campo ownerReference, che punta all’oggetto proprietario. Il valore del campo ownerReference viene di default impostato automaticamente, ad esempio, durante la creazione di un controller: nel caso di un ReplicaSet, viene impostato il campo ownerReference per ogni pod nel ReplicaSet.
Ora che abbiamo una definizione, perché preoccuparsi di questi Pod?
Questi Pod orfani rappresentano un vero problema per gli utenti, anche se rappresentano una piccola percentuale del totale dei Pod nel sistema. Dove sono finiti, esattamente? Perché sono stati abbandonati? E, ancora, senza un vero codice di uscita, come può Kubernetes piuttosto che un utente sapere se è sicuro utilizzare nuovamente quel Pod o no?
Sappiamo che i Pod orfani vengono persi perché il nodo sottostante scompare. I nodi possono scomparire per qualsiasi motivo, soprattutto nel “cloud”: quando ciò accade, di solito un controller cloud fornito dal provider rileverà che il server, ad esempio un’istanza EC2 in AWS, è effettivamente scomparso e, a sua volta, eliminerà l’oggetto relativo su Kubernetes, mentre un processo di GC eliminerà il pod.
Questo meccanismo spiega cosa accade, ma non fornisce una spiegazione sul perché sia avvenuto ciò.
Un caso di studio interessante che mostra come stabilire la causa del problema è quello di Titus, la piattaforma di gestione dei container open source utilizzata da Netflix: come descritto in questo post, loro utilizzano un controller per salvare la cronologia degli oggetti Pod e Node, in modo da poter salvare alcune spiegazioni e mostrarle agli utenti.
Tramite l’utilizzo di un’annotazione posta all’interno della definizione dei Pod, e l’utilizzo di un controller che legga lo stato relativo al nodo che ospita il Pod, il cluster sarà in grado di ottenere una spiegazione su cosa sia accaduto al Pod scomparso.
Segnalare che un Pod non è stato in esecuzione come ci si aspettava a causa di kernel panic potrebbe non sembrare così importante per gli utenti finali, ma disporre di strumenti di osservabilità come questo è necessario per rendere la piattaforma a prova di bomba!
Risorse utili
🔗 Leggi anche:
Articoli Correlati








