Perché usare Docker per il machine learning

“Sul mio PC funziona”.
Questa è la classica frase con cui, chi lavora nel settore IT -e non solo- ha a che fare quotidianamente e che porta ad ore di revisioni, controlli e confronti.
Se poi si parla di applicazioni che riguardano il machine learning, basta immaginarsi di dover avere a che fare con questioni come l’installazione di dipendenze, requisiti di sistema, CPU, GPU e altro ancora per desistere da ogni tentativo.
E se tutto questo potesse diventare marginale?
In questo, il mondo DevOps può arrivare in soccorso di chi vuole lavorare a costo -quasi- zero e rendendo lo stereotipo “sul mio PC funziona” uno stile di vita.
Vediamo come sfruttare la forza di Docker per combinarla con il mondo del machine learning e creare una fusione dalla potenza incredibile.
Premesse
Una premessa è doverosa: chi di noi ha un passato da sviluppatrice/sviluppatore, sa bene che lavorare sul proprio PC è tutt’altro che emozionante: si passa più tempo a litigare con gli aggiornamenti, le installazioni e le dipendenze, che a scrivere codice.
Sia chiaro: pretotipare e prototipare sul proprio laptop è bellissimo ed è quello che, bene o male, facciamo tutti. Quando poi si ha bisogno di lavorare insieme a qualcuno, si sfruttano GitHub o simili per condividere il proprio codice e lavorare a più mani.
E se avessi bisogno di maggiore potenza? Ecco che molti dei cloud provider che sono sul mercato vengono in nostro soccorso, fornendo delle macchine on-demand che possiedono certamente più CPU e GPU di quanta ce ne potremmo mai permettere allo stesso costo.
In questo scenario, qual è la necessità di ricorrere ai container, o perfino a Docker?
I container non sono quei pezzi di metallo nei porti che ci aiutano ad avere ogni giorno ciò di cui abbiamo bisogno?
Scherzi a parte, i container sono spesso considerati qualcosa di assolutamente esotico, normalmente relegato alle responsabilità di sistemisti&co. che sono reputati i veri esperti del tema e che si occuperanno -con della magia, non c’è dubbio- di far funzionare il tuo codice.
… se non fosse che in questo settore la competizione è spesso così alta, che bisogna saper fare un po’ di tutto, e soprattutto per chi ama questo lavoro, aggiungere un’altra tacchetta al proprio CV fa sempre bene.
Andiamo quindi ad analizzare in prima battuta quali sono le problematiche che possono venir fuori quando si ha a che fare con del software che sfrutta tecniche e librerie di machine learning, e poi perché dovremmo considerare l’idea di usare i container contro i nostri malditesta.
Caso di studio
Immagina di avere a che fare con un progetto che richiede la creazione di un sistema per il riconoscimento delle immagini che sia in grado di addestrare una rete generativa avversaria su dati mammografici per evidenziare caratteristiche di malignità utilizzando immagini radiografiche.
Per approfondire la tematica relativa alle reti GAN, leggi questo articolo.
Sembra un’attività piuttosto ambiziosa, no?
In realtà, richiede l’utilizzo di diversi ingredienti, come potenza di computazione, memoria, librerie, backup (non si sa mai…) e via dicendo. Tutto questo può essere configurato in locale o, ancora meglio, su una macchina EC2, a cui accedere tramite SSH e far sì che sia il server a farsi carico del lato operativo!
Quindi, cosa c’è di sbagliato in questa configurazione? Niente, in realtà: la maggior parte delle configurazioni di sviluppo ha avuto questo aspetto per decenni: nessun cluster, nessun file system condiviso, versionamento del codice per coordinare diversi team…
Fatta eccezione per una piccola comunità di ricercatori nell’ambito della High-Performance Computing (HPC) che sviluppano codice e lo eseguono su supercomputer, il resto di noi si affida alle nostre macchine dedicate per lo sviluppo.
A quanto pare, il machine learning ha più cose in comune con l’HPC che con lo sviluppo software tradizionale. Come i carichi di lavoro che richiedono HPC, i carichi di lavoro possono beneficiare di un’esecuzione più rapida e di una sperimentazione più rapida quando vengono eseguiti su un cluster di grandi dimensioni.
Però, per poter sfruttare un cluster in cui effettuare delle attività di machine learning, devi assicurarti che il tuo ambiente di sviluppo sia portabile e che l’addestramento sia riproducibile su un cluster.
Portabilità
Ad un certo punto del tuo lavoro di sviluppo del machine learning, andrai a scontrarti con uno di questi problemi:
- Stai sperimentando diverse cose e hai troppe varianti dei tuoi script di addestramento da eseguire, per cui sei bloccato perché non hai sufficienti risorse per parallelizzare le attività;
- Stai eseguendo l’addestramento su un modello di grandi dimensioni con un set di dati enorme e non è possibile eseguirlo sul tuo laptop, ottenendo anche risultati in un ragionevole lasso di tempo.
Questi due casi portano a momenti di forte frustrazione e sono proprio la ragione per cui utilizzare dei container su un cluster potrebbe essere una buona idea. Se decidessi di prendere questa via, allora la prima cosa su cui è necessario concentrarsi è la portabilità.
Concetto sconosciuto ai più, o scontato per chi è del mestiere, è la caratteristica fondamentale che ha fatto di Docker una società incredibile nel giro di pochi anni.
Infatti, la portabilità rappresenta la capacità di astrarre la soluzione software da dipendenze, configurazioni hardware e software come le risorse a disposizione o il sistema operativo, e rendere la nostra soluzione funzionante su qualsiasi ambiente fornendo delle semplici indicazioni.
Un po’ come quando ci passano la ricetta della parmigiana di nonna con tutti gli ingredienti e il procedimento, e noi dobbiamo “solo” prepararla…
Scherzi a parte, è molto più semplice di questo, ed entrambe le soluzioni descritte in precedenza richiedono che tu sia in grado di riprodurre correttamente e in modo coerente la tua configurazione di training per lo sviluppo su un cluster.
Questa è sicuramente la parte più impegnativa perché il cluster potrebbe eseguire diversi sistemi operativi e versioni del kernel; diverse GPU, driver e runtime; e diverse dipendenze software rispetto alla macchina di sviluppo, per cui bisogna pensare a quali sono le reali necessità per far sì che la soluzione funzioni.
Un altro motivo per cui hai bisogno di ambienti di machine learning portabili è per lo sviluppo collaborativo: condividere il tuo lavoro con altri colleghi tramite il versionamento del software è facile.
Garantire la riproducibilità dell’output della soluzione senza condividere l’intero ambiente di esecuzione con codice, dipendenze e configurazioni è più difficile, come vedremo a breve.
Dipendenze, hardware&co.
Una sfida per chi lavora con il machine learning è che bisogna basarsi su framework e toolkit di machine learning open source spesso complessi e in continua evoluzione che funzionano su ecosistemi hardware moderni e complessi. Sono certo condizioni che rappresentano qualità positive, ma pongono sfide a breve termine.
Quante volte hai eseguito degli script con algoritmi di machine learning e ti sei post* queste domande:
- Il mio codice sfrutta tutte le risorse disponibili su CPU e GPU?
- Ho le librerie giuste per sfruttare l’hardware? Sono le versioni giuste?
- Perché il mio codice di addestramento funziona bene sulla mia macchina, ma si blocca su quella del mio collega, quando gli ambienti sono più o meno identici?
- Ho aggiornato i miei driver oggi e la formazione ora è più lenta/errori. Come mai?
- Perché sul mio PC funziona e su quello di Caio no?
Se potessimo disegnare il modo in cui spendiamo il nostro tempo su questo dipo di attività, sarebbe più o meno fatto così:
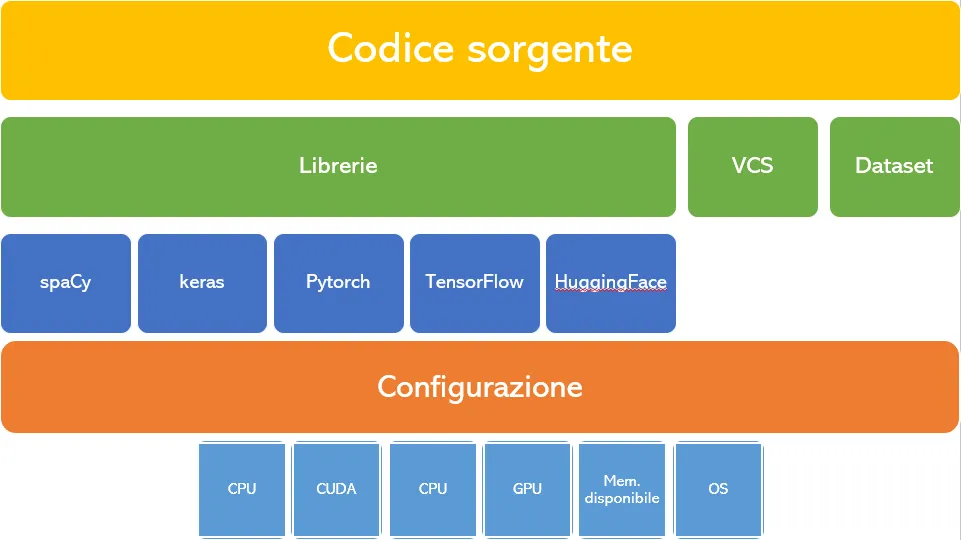 Stack tradizionale di un’applicazione per il ML
Stack tradizionale di un’applicazione per il ML
Se dai un’occhiata da vicino, noterai che trascorri la maggior parte del tuo tempo nella seconda parte del disegno, chiamato “configurazione”. Ciò include la configurazione dell’ambiente, delle librerie, la verifica delle dipendenze, l’aggiornamento delle stesse, l’installazione dell’ennesima libreria che ti eri perso, la configurazione del repository Git, e via dicendo.
Come se ciò non fosse abbastanza complesso, sai bene che le librerie vengono aggiornate continuamente, che tra una versione x della libreria y e la sua versione con quel minor fix che ti serve proprio, c’è di mezzo una crisi nevrotica. Non solo: ci sono librerie che funzionano solo su macchine che hanno la GPU, e quella libreria a te risparmierebbe tanto tempo…
Quanto tempo rimane al codice? Tanto, certamente, ma il tempo di esecuzione? Porta a molti tempi morti che diventano l’attesa di un risultato che, se porta degli errori, richiede la revisione dell’interno processo.
A causa dell’elevata complessità di uno stack software come quello necessario al machine learning, quando passi il codice sul computer di un collega o in un ambiente cluster, rischi di aumentare i punti di errore.
Infatti, tutto ciò che è stato evidenziato, rappresenta un punto di rottura dell’intero processo, che porta al fallimento dei tuoi esperimenti.
Potresti a questo punto però obiettare pensando che, per questo, esiste l’ambiente virtuale, come grazie ad Anaconda; in parte è vero, questi strumenti astraggono il tuo lavoro, ma solo in parte.
Diverse dipendenze non Python -che però Python usa- non sono gestite da queste soluzioni. A causa della complessità di un tipico stack di machine learning, gran parte delle dipendenze del framework, come le librerie hardware, non rientrano nell’ambito degli ambienti virtuali.
Lunga vita ai container
A questo punto, cerchiamo di elencare tutti i possibili punti di fallimento del nostro lavoro, riprendendo le immagini viste in precedenza.
Sappiamo che il software che stiamo progettando fa parte di un ecosistema frammentato su più parti di codice e con diverse persone che vi collaborano.
La collaborazione è un’ottima cosa, poiché tutti beneficiano dei contributi di tutti e il tuo lavoro potrebbe tornare utile a qualcuno. Il rovescio della medaglia è affrontare problemi come la coerenza, la portabilità e la gestione delle dipendenze.
È qui che entrano in gioco le tecnologie dei container. In questo articolo non discuterò i vantaggi generali dei container -che puoi trovare qui-, ma parleremo solo dei vantaggi che apporta al nostro lavoro di machine learning.
I container possono incapsulare completamente non solo il codice di training, ma l’intero stack di dipendenze fino ad arrivare alle librerie hardware.
Quello che ottieni è un ambiente di sviluppo di machine learning coerente e portabile. Con i container, sia la collaborazione che la scalabilità su un cluster diventano molto più semplici.
Se sviluppi codice ed esegui il training in un container, puoi condividere comodamente non solo i tuoi script, ma l’intero ambiente di sviluppo, aggiornando l’immagine del container tramite un registry e chiedendo a un collega o a un servizio di automazione di estrarre l’immagine del container e di aggiornare l’ambiente in esecuzione per riprodurre i risultati.
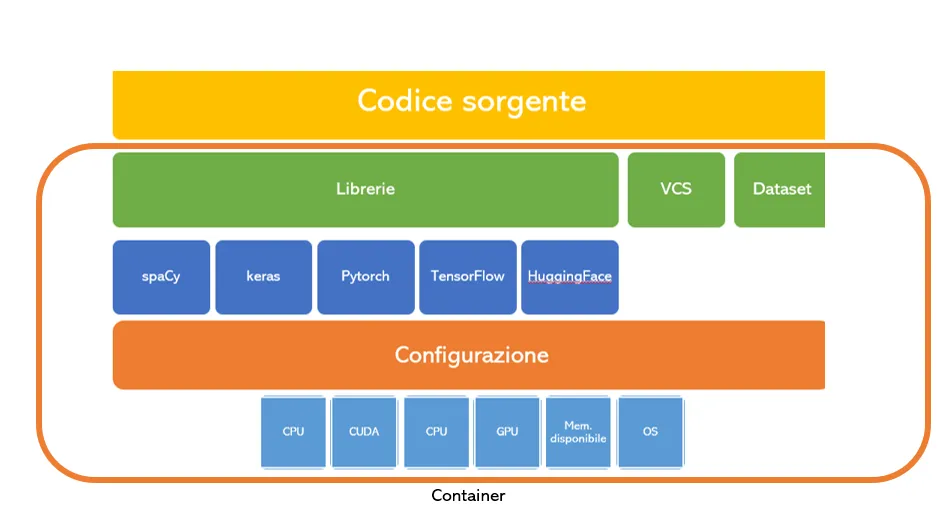 Esempio di containerizzazione di un’applicazione per il ML
Esempio di containerizzazione di un’applicazione per il ML
L’approccio giusto che ci porta a risparmiare del tempo e ci fa guadagnare terreno nel nostro lavoro è quello che considera di includere dipendenze e framework all’interno del container, fornendo (o includendo) il codice di training del tuo processo tramite la definizione di un’immagine.
Questo permette di lavorare esclusivamente agli aspetti che riguardano la gestione del processo di addestramento, e lasciare che la configurazione generica sia gestita interamente dal container, che installerà tutto ciò che gli viene indicato e si occuperà solo di processare l’input.
Anche condividere e modificare l’immagine di sviluppo è facile. Nell’ambiente di lavoro possiamo infatti andare a configurare un registry che tenga memoria delle versioni prodotte delle nostre immagini, per poterne effettuare il deploy secondo le esigenze.
Per questo, AWS mette a disposizione dei container grazie a AWS Deep Learning Container, i quali contengono i più diffusi framework di deep learning open source e che sono necessitano di CPU e GPU ottimizzate per il calcolo.
Caso d’uso
Torniamo all’esempio fatto inizialmente: vogliamo costruire sistema che sia in grado di riconoscere, utilizzando delle immagini mammografiche, possibili masse relative a carcinoma di origine benigna o maligna.
Per portare avanti un’idea del genere, di sicuro avremo bisogno di utilizzare librerie come Pytorch o Tensorflow. Peccato che il mio PC abbia più di cinque anni e abbia una versione di Windows abbastanza obsoleta. Come fare?
Dopo aver creato un account gratuito su AWS, posso andare a creare un’istanza EC2. Per chi non ne avesse mai sentito parlare, si tratta di un servizio che mette a disposizione delle macchine con diverse caratteristiche, a seconda delle esigenze.
Ad esempio, quelle che appartengono alle famiglie C, P o G, sono perfette se abbiamo bisogno di potenza computazionale, così come le suddette librerie richiedono.
Inoltre, possiamo scegliere tra diverse AMI (abbreviazione di Amazon Machine Image) che ci permettono di avviare delle macchine con tutto l’occorrente già pronto e installato: perché non utilizzare allora un container già pronto?
Esistono infatti diversi container che hanno TensorFlow o PyTorch già installato, con una serie di librerie annesse: l’elenco completo di quelle messe a disposizione è disponibile nella documentazione fornita da AWS.
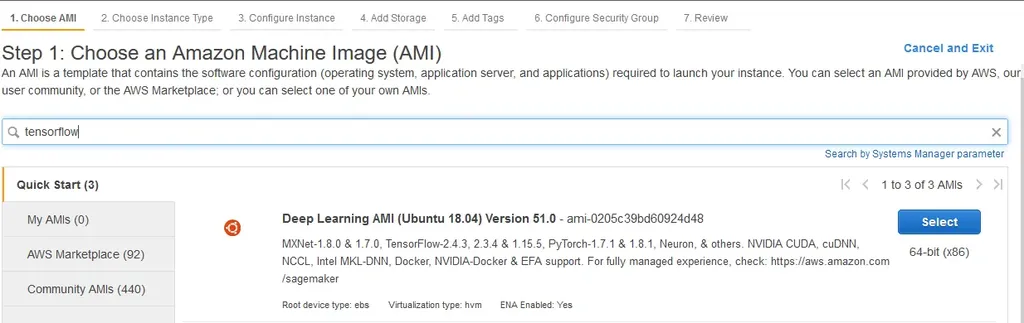 Esempio di AMI per il Deep Learning con TensorFlow
Esempio di AMI per il Deep Learning con TensorFlow
Una volta avviata l’istanza di EC2, sarà sufficiente avviare il container di TensorFlow con un comando simile al seguente (verificando la region specificata, che in questo caso è quella europea in Irlanda):
docker pull 763104351884.dkr.ecr.eu-west-1.amazonaws.com/tensorflow-training:2.1.0-gpu-py36-cu101-ubuntu18.04
docker run -it --runtime=nvidia -v $PWD:/projects --network=host --name=tf-dev 763104351884.dkr.ecr.eu-west-1.amazonaws.com/tensorflow-training:2.1.0-gpu-py36-cu101-ubuntu18.04
Dopodiché, dovremo solo installare il modulo jupyterlab tramite pip e avviare un nuovo laboratorio, che ci permetterà di lavorare e testare il codice sorgente in maniera più agile:
pip install jupyterlab
jupyter lab --ip=0.0.0.0 --port=9999 --allow-root --NotebookApp.token='' --NotebookApp.password=''
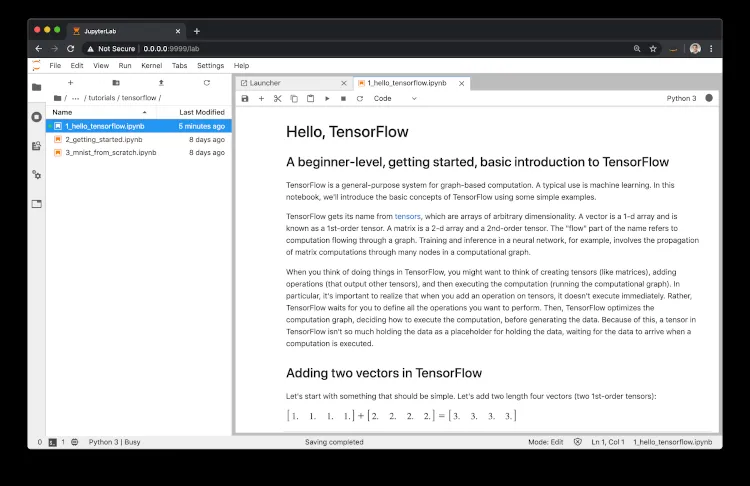 Avvio di un Jupyter notebook
Avvio di un Jupyter notebook
Immaginando di lavorare direttamente in questo ambiente e di modificare quindi il container di base di cui abbiamo effettuato il pull in precedenza, arriveremo ad un punto in cui sarà necessario salvare il lavoro fatto: per questo, c’è docker commit.
Nel momento in cui la nostra immagine sarà pronta e vorremo condividerla con gli altri colleghi, potremo sfruttare o un repository disponibile su Docker Hub, o anche Amazon Elastic Container Registry:
aws ecr create-repository --repository-name my-tf-dev
$(aws ecr get-login --no-include-email --region <REGION>)
docker tag my-tf-dev:latest <ACCOUNT_ID>.dkr.ecr.<REGION>.amazonaws.com/my-tf-dev:latest
docker push <ACCOUNT_ID>.dkr.ecr.<REGION>.amazonaws.com/my-tf-dev:latest
Tutto ciò che ho fatto finora, mi permette di essere cert* al 100% che il mio lavoro funzionerà esattamente come l’ho progettato su qualunque altra infrastruttura: sarà sufficiente utilizzare l’immagine caricata nel repository e avviarla.
Semplice, no?
Verso la conclusione
Arrivati a questo punto, potrebbe sorgere spontanea la domanda: e perché io, che mi occupo di data science, machine learning e via discorrendo, dovrei mettermi a gestire tutto questo?
Certo, c’è un notevole risparmio di tempo e di possibili problematiche, ma non conoscendo così bene strumenti di orchestrazione, non avendo familiarità con tematiche come la gestione di un cluster, avrei difficoltà con un approccio del genere.
Ecco l’asso nella manica: Amazon SageMaker. Si tratta di un servizio completamente gestito dove tutta la parte relativa alla configurazione di Jupyter, dell’ottimizzazione degli_hyperparameters_ e dei nodi che ospiteranno la nostra applicazione (sì, per quando diventeremo grandi), è in mano ad Amazon.
La nostra unica attività sarà quella di definire l’immagine da utilizzare: al resto, penserà SageMaker.
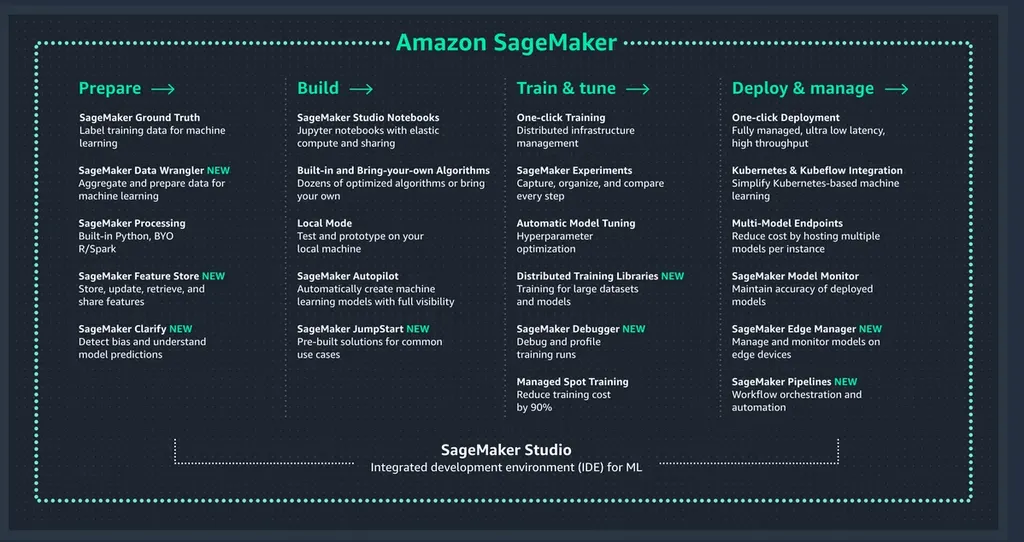 Funzionalità di Amazon SageMaker
Funzionalità di Amazon SageMaker
Visto il nostro caso d’uso, avere a disposizione della potenza computazionale sufficiente allo scopo è fondamentale per ottenere un buon risultato.
Ad esempio, AWS fornisce la possibilità di utilizzare Apache MXNet, ossia un framework di addestramento e inferenza veloce e scalabile integrata da un’API per attività di machine learning e deep learning.
MXNet include l’interfaccia Gluon, che permette agli sviluppatori a qualsiasi livello di competenza di iniziare con il deep learning su cloud, per creare regressione lineare, reti convoluzionali e reti LSTM ricorrenti per il rilevamento di oggetti, il riconoscimento vocale, riconoscimento di immagini e via dicendo.
La community dietro al mondo del machine learning si muove velocemente. Esistono migliaia di ricerche che vengono portate avanti ogni giorno, grazie alla pubblicazione di API e framework open source sempre aggiornati.
Un approccio come questo ci garantisce molti vantaggi, come la possibilità di concentrarci sullo sviluppo, senza preoccuparci di non avere sufficiente potenza computazionale o di rendere difficile la collaborazione e la fruizione del nostro lavoro.
Quando il software si evolve così rapidamente, tenere il passo con le ultime novità e mantenere la qualità, la coerenza e l’affidabilità di ciò a cui lavori può essere difficile…
…ma non c’è bisogno di preoccuparsi. Passare allo sviluppo di attività di ML tramite container è un modo per affrontare queste sfide, come spero sia emerso in questo articolo sul perché usare Docker per il machine learning!



