Addestramento NER con spaCy per nuove entità

“Named Entity Recognition”: letteralmente significa riconoscere le entità. Con Python, è un’attività piuttosto semplice, grazie alla potenza di librerie come spaCy che forniscono dei modelli pronti all’uso per riconoscere oggetti comuni come luoghi, persone, brand, e molto altro.
E se volessi aggiornare il modello con delle nuove categorie?

In questo post parliamo di come addestrare spaCy per riconoscere nuove entità! L’ambito dell’analisi del linguaggio non è affatto nuovo -nonostante sia credenza usuale pensarlo-.
Cosa vedrai
Cos’è la NER
Il riconoscimento delle entità (in inglese, Named Entity Recognition) è il processo di identificazione automatica delle entità presenti in un testo e di conseguente classificazione in categorie predefinite come “persona”, “organizzazione”, “posizione” e così via. La libreria spaCy ti consente di utilizzare modelli per il NER già addestrati, ma anche di aggiornarli per adattarli al contesto specifico delle informazioni a nostra disposizione, o ancora di addestrare un nuovo modello da zero.
La realtà è che questi modelli sono molto sviluppati in inglese e possono riconoscere date, eventi, lingue, località, numeri, percentuali, organizzazioni, persone, prodotti, quantità e molto altro, ma non lo sono in lingue come l’italiano: il numero di entità riconosciute si conta con una sola mano. Per averlo chiaro, vediamo come dovrebbe funzionare_,_ e come invece funziona:

Come dovrebbe funzionare la NER
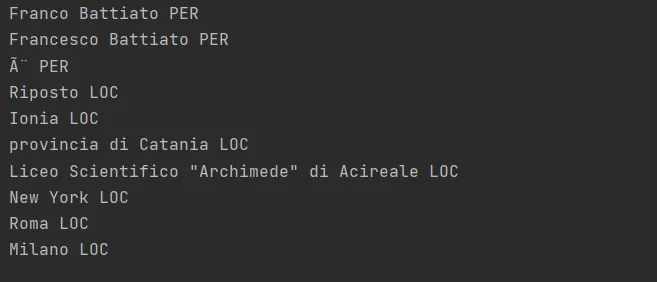
Come invece funziona
Facciamo un passo alla volta: vediamo in che modo questo modello funziona e come utilizzarlo!
Come funziona la NER
Per far sì che venisse fuori un risultato come quello precedente, i passi sono davvero semplici: per prima cosa, è necessario avere una versione di Python 3.x e, nel nostro caso, aver scaricato il modello per l’italiano: sempre tramite il sito di spaCy, è possibile scegliere quale modello utilizzare a seconda della lingua e del tipo di lavoro da effettuare. Nel nostro caso, andremo ad utilizzare il modello più grande denominato it_core_news_ls.
python -m spacy download it_core_news_lg
Piccola precisazione: è possibile anche partire da zero, costruendo un modello da zero, ma non è questo il caso: noi vogliamo piuttosto integrare delle informazioni in quello disponibile.
Dopo averlo scaricato grazie al precedente comando, passiamo al funzionamento: lo vado a caricare tramite la funzione di spaCy load() e, partendo da un semplice file di testo che contiene il testo che vogliamo classificare, andiamo a stampare per ogni entità riconosciuta, l’etichetta assegnata:
import spacy
# Carico modello precedente
nlp = spacy.load('it_core_news_lg')
with open('articolo.txt') as file:
article = file.read()
# Applico modello su file
doc = nlp(article)
for ent in doc.ents:
print(ent.text, ent.label_)
Come vediamo, il risultato è abbastanza buono: riconosce Franco Battiato e Francesco Battiato come persone, Riposto e Ionia come luoghi, e via dicendo. Considerando che si tratta di un testo abbastanza semplice, quello che ci viene restituito è accettabile.
E se invece del testo sulla biografia di Franco Battiato (buon viaggio, maestro!), volessimo poter etichettare delle nuove entità? Abbiamo visto che per l’italiano, le possibilità sono poche: luoghi, organizzazioni, persone o altre entità che vengono (spesso erroneamente) categorizzate come “miscellaneous”.
Come aggiornare il modello
Ad esempio, proviamo a mettere il nostro modello in grado di riconoscere il cibo: l’esempio che andremo a esaminare è volutamente semplice, perché serve a rendere l’idea del lavoro da svolgere per arrivare a un buon risultato, ma è altrettanto semplice estenderlo.
Per prima cosa, raccogliamo in un file di testo una decina di frasi che parlino di cibo, in questo modo:
Ho comprato del latte. Federico adora la cioccolata. Io e mio cugino andiamo matti per le lasagne. Per preparare la pasta, è sufficiente mettere una pentola d'acqua sul fuoco... Per preparare il tiramisù, hai bisogno di... I savoiardi dovranno essere imbevuti di caffè e poi adagiati in una pirofila. Il gelato alla nocciola è il mio preferito. Hai mai assaggiato le lasagne al pesto? Per cena cucinerò della pasta. Non mi va di cucinare stasera. Ordiniamo della pizza?
Questi sono esempi scritti a mano, ma sarebbe opportuno avere un vero dataset, che sia molto più completo e ampio: su questo argomento ci torneremo un’altra volta. Fatto questo, andiamo a creare un oggetto fatto in questo modo:
TRAIN_DATA = [
("Prima di tutto dividete i tuorli dagli albumi e metteteli in due ciotole diverse.",
{"entities": [(27, 33, "ALIMENTO"), (40, 46, "ALIMENTO")]}),
("Unite un cucchiaio di zucchero", {"entities": [(22, 30, "ALIMENTO")]}),
("unire il mascarpone", {"entities": [(9, 19, "ALIMENTO")]}),
("mescolare le uova", {"entities": [(13, 17, "ALIMENTO")]}),
("ricopritela con uno strato di savoiardi imbevuti nella bagna", {"entities": [(30, 39, "ALIMENTO")]}),
("Mescolate con il liquore al caffè", {"entities": [(18, 25, "ALIMENTO"), (29, 34, "ALIMENTO")]}),
("Usare lo sbattitore", {"entities": []}),
("Mangiare la pizza una volta a settimana è d'obbligo", {"entities": [(12, 17, "ALIMENTO")]}),
("Ho comprato del latte.", {"entities": [(17, 22, "ALIMENTO")]}),
("Marco adora la cioccolata.", {"entities": [(16, 26, "ALIMENTO")]}),
("Io e mio cugino andiamo matti per le lasagne.", {"entities": [(38, 45, "ALIMENTO")]}),
("Per preparare la pasta, è sufficiente mettere una pentola d'acqua sul fuoco...",
{"entities": [(18, 23, "ALIMENTO"), (61, 66, "ALIMENTO")]}),
("Per preparare il tiramisù, hai bisogno di...", {"entities": [(18, 26, "ALIMENTO")]}),
("I savoiardi dovranno essere imbevuti di caffè e poi adagiati in una pirofila.",
{"entities": [(3, 12, "ALIMENTO")]}),
("Il gelato alla nocciola è il mio preferito.", {"entities": [(4, 10, "ALIMENTO"), (16, 24, "ALIMENTO")]}),
("Hai mai assaggiato le lasagne al pesto?", {"entities": [(23, 30, "ALIMENTO"), (34, 39, "ALIMENTO")]}),
("Per cena cucinerò della pasta.", {"entities": [(20, 25, "ALIMENTO")]}),
("Non mi va di cucinare stasera. Ordiniamo della pizza?", {"entities": [(47, 53, "ALIMENTO")]})
]
Si tratta di un array di tuple, dove ogni tupla è costituita da una stringa rappresentante la frase da cui imparare, mentre la seconda parte rappresenta le entità: queste sono a loro volta definite tramite un array che ne stabilisce la posizione dell’oggetto che vogliamo il nostro modello impari e l’etichetta che vogliamo assegnargli; infatti, nel caso nella nostra frase ci siano più alimenti, è bene segnalarli tutti.
("Prima di tutto dividete i tuorli dagli albumi e metteteli in due ciotole diverse.",
{"entities": [(27, 33, "ALIMENTO"), (40, 46, "ALIMENTO")]}),
Fatto questo, andiamo ad aggiungere le varie entità all’interno delle labels a disposizione del modello di riconoscimento, in questo modo:
for _, annotations in TRAIN_DATA:
for ent in annotations.get("entities"):
ner.add_label(ent[2])
Arriviamo al cuore dell’attività: dobbiamo addestrare ed aggiornare il nostro modello. Per farlo, andremo a eseguire 30 iterazioni (o epoche) in cui, per ognuna di queste, i dati saranno rimescolati e andremo a calcolare i valori in termini di losses: significa che utilizzeremo un dizionario per mantenere le informazioni relative alle “perdite” rispetto a ciascun componente della pipeline.
In altre parole, l’addestramento è un processo iterativo basato su reti neurali in cui le previsioni del modello vengono confrontate man mano che questo avviene, per poter stimare quello che si chiama gradiente.
Questo viene infatti utilizzato per calcolare il valore dei pesi attraverso la retropropagazione degli errori. I gradienti indicano come modificare i valori di peso in modo che le previsioni del modello diventino più simili alle etichette da assegnare. Ma mano che i valori di loss diminuiscono, il nostro modello è sempre più vicino all’esser pronto a lavorare per noi!
Inoltre, utilizzeremo i batch, che sono molto utili quando si deve suddividere l’input iniziale in gruppi più piccoli: in questo caso, utilizzeremo 2 coppie di frasi (vedi riga con parametro size=2) per ogni minibatch.
Per ogni frase contenuta nel nostro insieme di addestramento di partenza e per ogni gruppo di entità, andremo a creare un oggetto Example: questo strumento appartenente sempre alla libreria di spaCy è fondamentale per creare gli oggetti con cui il modello potrà “aggiornarsi”, e lo farà grazie alla funzione update.
Ultimo, non ultimo, il valore di drop: questo rappresenta il cosiddetto dropout rate e si tratta di una tecnica che usano le reti neurali per ridurre l’eccessivo adattamento all’insieme di addestramento.
Può infatti succedere che il modello impari troppo alla lettera dagli esempi che gli forniamo e quindi non sappia generalizzare: in questo caso, sarebbe utile come un pappagallo a cui insegnamo a dire “cioccolato”!
Il valore per il dropout di default è di 0.2: questo vuol dire che il 20% dei neuroni utilizzati nel modello verrà eliminato in maniera casuale dall’addestramento, per rendere più robusto il modello. In questo caso, impostiamo a 0.3, visto che il nostro dataset iniziale è molto piccolo:
\# Import delle librerie
import random
from spacy.util import minibatch, compounding
from pathlib import Path
from spacy.training import Example
# Addestramento del modello
with nlp.disable_pipes(\*unaffected_pipes):
# Per 30 iterazioni
for iteration in range(30):
# Shuffle dei dati prima di ogni iterazione
random.shuffle(TRAIN_DATA)
losses = {}
batches = minibatch(TRAIN_DATA, size=compounding(4.0, 32.0, 1.001))
for batch in spacy.util.minibatch(TRAIN_DATA, size=2):
for text, annotations in batch:
# Creo l'oggetto example
doc = nlp.make_doc(text)
example = Example.from_dict(doc, annotations)
# Aggiorno il modello
nlp.update([example], losses=losses, drop=0.3)
print("Losses", losses)
Una volta che il nostro modello è stato creato, andiamo a salvarlo: in questo modo, sarà possibile utilizzarlo come base di partenza, proprio come abbiamo fatto all’inizio sfruttando quello già disponibile chiamato it_core_news_lg: lo salviamo all’interno della cartella ner e lo carichiamo nuovamente, per andarlo a testare.
doc = nlp("Il tiramisù richiede il mascarpone")
print("Entità:", [(ent.text, ent.label_) for ent in doc.ents])
# Salvo il modello
output_dir = Path('/ner/')
nlp.to_disk(output_dir)
print("Salvato nella cartella: ", output_dir)
Test
Così come abbiamo fatto con il primo step, carichiamo tramite la funzione load di spaCy il modello e poi andiamo a inserire delle frasi nuove, per vedere come lavora:
\# Carico modello
print("Carico modello dalla cartella: ", output_dir)
nlp_updated = spacy.load(output_dir)
doc = nlp_updated("Amo il tiramisù con i savoiardi e la pizza con la mozzarella")
print("Entità:", [(ent.text, ent.label_) for ent in doc.ents])
doc = nlp_updated("Per preparare le tagliatelle, ci vuole la farina")
print("Entità:", [(ent.text, ent.label_) for ent in doc.ents])
doc = nlp_updated("Marco adora la marmellata")
print("Entità:", [(ent.text, ent.label_) for ent in doc.ents])
Andiamo ad eseguire e…
Losses {'ner': 13.718762298731333} Losses {'ner': 3.8097394014000354} Losses {'ner': 3.809832848429478} Losses {'ner': 5.24418013019176} Losses {'ner': 5.251497398704705} Losses {'ner': 5.252461936261976} Losses {'ner': 5.252638007338877} Losses {'ner': 7.138335501468781} Losses {'ner': 10.640419887586425} Losses {'ner': 10.643248762972322} Losses {'ner': 1.9226063930241843} Losses {'ner': 3.5654583980540644} Losses {'ner': 5.100164967156944} Losses {'ner': 6.197872385207523} ... Losses {'ner': 0.0012744452799972822} Losses {'ner': 0.001274446825658949} Losses {'ner': 0.0012744472823863233} Losses {'ner': 0.0013462597426898537} Entità: [('mascarpone', 'ALIMENTO')] Salvato nella cartella: \\ner Carico modello dalla cartella: \\ner Entità: [('savoiardi', 'ALIMENTO'), ('pizza', 'ALIMENTO'), ('mozzarella', 'ALIMENTO')] Entità: [('farina', 'ALIMENTO')] Entità: [('marmellata', 'ALIMENTO')]
Da notare una cosa: parole come “farina”, “mozzarella” e “marmellata” non erano incluse nell’insieme di addestramento, ma sono state etichettate correttamente: questo perché il modello non viene addestrato a riconoscere le parole esatte, piuttosto impara a dedurne il contesto e quindi a trarre conclusioni su quali parole possano corrispondere a quella categoria, in modo da poter generalizzare il suo uso… ed è questa la parte incredibile!

Risorse utili
- Analisi del linguaggio naturale con Python
- Repository GitHub
- Guida from zero to hero (EN): spaCy 101
- Le reti neurali in 5 minuti (video)
- Intelligenza artificiale for dummies (libro)
- Machine learning for dummies (libro)
- Python: guida completa (libro)



