Testiamo AI Playground di PyCharm con Ollama
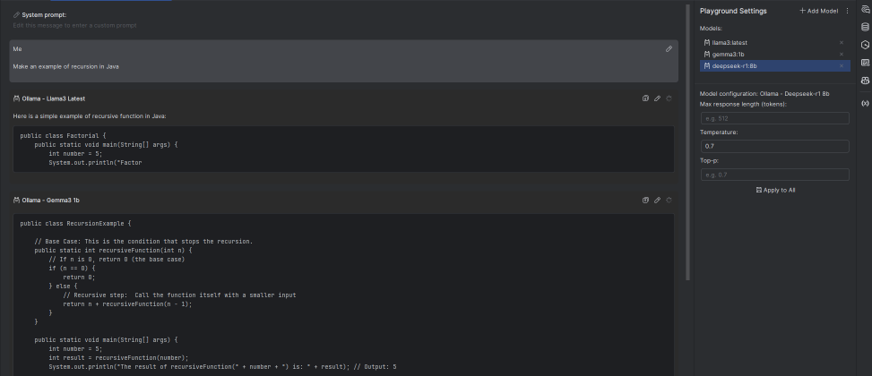
Hai già provato AI Playground di PyCharm? Scopri come usarlo con i modelli locali di Ollama per uno sviluppo assistito da LLM!
AI Playground e PyCharm: cos’è
AI Playground è una funzionalità integrata nell’IDE PyCharm di JetBrains che porta i modelli linguistici direttamente nel tuo ambiente di sviluppo. Introdotto per democratizzare l’accesso agli strumenti di AI durante la programmazione, AI Playground permette a chi sviluppa di interagire con modelli di linguaggio avanzati senza abbandonare l’IDE.
Questa funzionalità si distingue da altri assistenti AI perché è progettata specificamente per il workflow di sviluppo. Non si tratta solo di un chatbot integrato, ma di un vero e proprio ambiente dove testare prompt, generare codice, analizzare problemi e ottenere spiegazioni tecniche contestualizzate al progetto su cui stai lavorando, anche parallelizzando l’uso di diversi modelli per confrontare risposte e performance.
Caratteristiche principali:
- Integrazione nativa con l’ecosistema JetBrains
- Supporto per modelli cloud e locali
- Context awareness del codice del progetto
- Interfaccia dedicata per l’interazione con AI
- Gestione avanzata di prompt e conversazioni
L’obiettivo è trasformare l’IDE da semplice editor a partner intelligente per lo sviluppo, capace di comprendere il contesto del tuo lavoro e fornire assistenza mirata.
Come funziona
AI Playground opera attraverso un’architettura modulare che separa l’interfaccia utente dal motore di AI sottostante. Questo design permette una grande flessibilità nella scelta dei modelli e dei provider.
Cosa supporta?
Code Generation: Genera funzioni, classi o interi moduli partendo da descrizioni in linguaggio naturale.
# Prompt: "Crea una classe per gestire connessioni HTTP con retry automatico"
# Output: Codice Python completo con gestione errori e retry logic
Code Explanation: Analizza codice esistente e fornisce spiegazioni dettagliate.
Debugging Assistance: Aiuta nell’identificazione e risoluzione di bug fornendo suggerimenti basati sul codice e sui traceback.
Refactoring Suggestions: Propone miglioramenti strutturali e di performance per il codice esistente.
Una delle caratteristiche più potenti è la context awareness. AI Playground può:
- Leggere il file corrente e i file correlati
- Comprendere la struttura del progetto
- Accedere ai metadati del linguaggio di programmazione
- Utilizzare informazioni sui framework e librerie installate
Questo permette risposte molto più precise e contestualizzate rispetto a chatbot generici.
Usare Ollama e i modelli locali
Ollama rappresenta una svolta per chi sviluppa e vuole sfruttare l’AI mantenendo controllo completo sui dati e sulla privacy. Si tratta di un runtime ottimizzato per eseguire modelli di linguaggio direttamente sulla propria macchina.
Installazione e configurazione di Ollama
Passo 1: Installazione
# Windows (tramite installer)
# Scarica da https://ollama.ai
# macOS
brew install ollama
# Linux
curl -fsSL https://ollama.ai/install.sh | sh
Passo 2: Download di un modello
I modelli di Ollama sono ottimizzati per l’esecuzione locale e devono essere scaricati prima dell’uso. Per farlo, in maniera analoga a docker pull, si usa il comando ollama pull:
# Modelli consigliati per sviluppo
ollama pull codellama:7b # Ottimo per code generation
ollama pull llama2:13b # Bilanciato per uso generale
ollama pull deepseek-coder:6.7b # Specializzato per programmazione
Una volta che il modello è scaricato, puoi verificarne la presenza con:
ollama list
Passo 3: Avvio del servizio
A questo punto, puoi avviare il server locale di Ollama che esporrà un’API compatibile con OpenAI:
ollama serve
# Il servizio sarà disponibile su http://localhost:11434
Configurazione in PyCharm
Per integrare Ollama con AI Playground, ti basterà aprire Pycharm, cliccare sulla sinistra nel menu “AI Playground” e seguire questi passi:
- Creare un nuovo playground: Clicca su “New Playground” e crea l’ambiente che userai per lavorare con i modelli scelti.
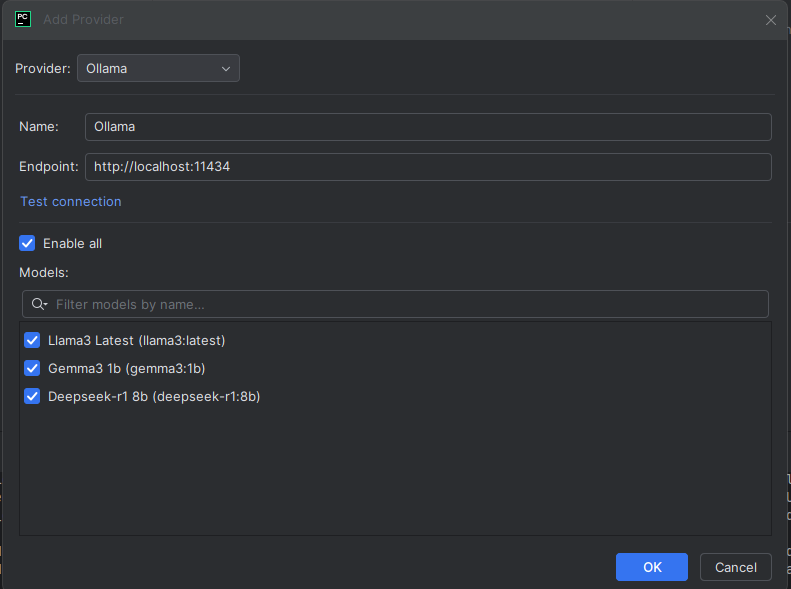
- Aggiungi provider personalizzato: Seleziona “Connect provider” e poi “Ollama”.
- Configura l’endpoint:
- URL:
http://localhost:11434 - Model: Nome del modello scaricato (es.
codellama:7b) oppure “Enable all”.
- URL:
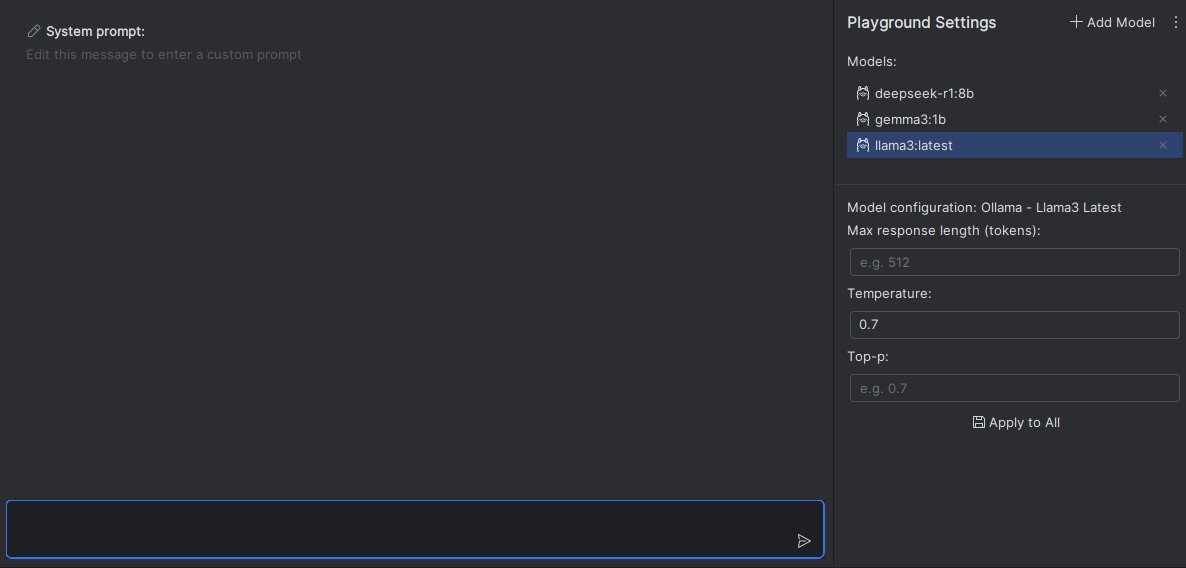
- Salva e inizia a usare: Ora puoi iniziare a interagire con il modello direttamente dal tuo IDE! L’aspetto interessante riguarda anche la configurazione del modello in termini di token, temperatura e top-p. Giusto per dare qualche informazione in più, la lunghezza massima in token ci permette di personalizzare l’output e quindi anche la qualità e i costi delle risposte. Inoltre, la temperatura influenza la creatività delle risposte (più bassa = più precisa, più alta = più varia, ma anche più soggetta ad allucinazioni). Il parametro top-p invece regola la probabilità cumulativa dei token considerati per la generazione della risposta: in altre parole, limita la scelta dei token ai più probabili fino a raggiungere la soglia p. Un valore più alto permette risposte più varie, mentre un valore più basso tende a generare risposte più conservative e prevedibili. la differenza tra la temperatura e il parametro top-p è che la temperatura agisce su tutta la distribuzione di probabilità, mentre il parametro top-p limita la scelta ai token più probabili fino a raggiungere la soglia specificata.
Vantaggi dei modelli locali
Ci sono diversi vantaggi nell’usare modelli locali con Ollama rispetto a soluzioni cloud, soprattutto se si è in una fase di sperimentazione (e non solo):
Privacy e sicurezza: Il codice non lascia mai la tua macchina, eliminando rischi di data leak o violazioni di policy aziendali.
Controllo completo: Puoi scegliere esattamente quale modello utilizzare, ottimizzarlo per le tue esigenze e personalizzare i parametri.
Costi prevedibili: Nessun costo per token o API call, solo l’investimento hardware iniziale.
Latenza ridotta: Le risposte sono spesso più veloci, non dipendendo dalla connessione internet.
AI Playground permette infatti di usare anche modelli in hosting cloud (come OpenAI, Azure, ecc.), ma l’integrazione con Ollama offre un equilibrio ideale tra potenza e controllo, oltre al fatto che usando modelli on-cloud significa dover gestire i costi associati e le limitazioni di utilizzo.
Ottimizzazione delle performance
Non ci sono indicazioni ufficiali sui requisiti hardware per eseguire Ollama, ma in generale più RAM e una buona GPU aiutano molto, soprattutto con modelli più grandi. Ecco qualche linea guida:
Requisiti hardware consigliati:
- RAM: Minimo 8GB per modelli 7B, 16GB+ per modelli 13B
- GPU: NVIDIA con almeno 6GB VRAM per accelerazione (opzionale ma consigliata)
- Storage: SSD per caricamento rapido dei modelli
Parametri di tuning:
# Esempio di configurazione personalizzata
ollama run codellama:7b --ctx-size 4096 --temp 0.1
ctx-size: Dimensione del contesto (più alto = più memoria del contesto)temp: Temperatura (più basso = risposte più deterministiche)
Questo tipo di funzionalità, integrata in un IDE come PyCharm, rappresenta un enorme passo avanti per i team di sviluppo che vogliono sfruttare l’AI senza compromettere la sicurezza o la privacy del loro codice. Con Ollama e AI Playground, JetBrains sta aprendo la strada a un futuro dove i modelli linguistici possono diventare un valido strumento di supporto quotidiano per chi sviluppa software, e non solo.



