AI e stregatti: il futuro dei LLM open source
Conosciamo lo Stregatto
Nelle ultime settimane si è parlato moltissimo di ChatGPT come dello strumento perfetto per chi sviluppa, per chi deve scrivere documentazione, ma non ha fantasia -o voglia- e perfino per chi ha bisogno di fare dei riassunti di storia per scuola.
Man mano che cresce la popolarità di questo strumento, arrivano anche le nuove funzionalità e rilasci, che però lasciano sempre più punti interrogativi: mentre OpenAI sta creando degli standard per utilizzare chat models che si discostano dai modelli di completamento, si crea un vincolo di chiusura verso l’utilizzo di OpenAI.
Chi sviluppa avrà un vincolo sempre più forte con questo prodotto, portando a una scelta molto simile a quel che succede quando ci si affida completamente ai servizi di un qualsiasi provider SaaS.
Il progetto del Cheshire Cat nasce dall’idea di avere un’applicazione che permetta di costruire dei sistemi di AI custom utilizzando qualsiasi language model.
Lo scopo è semplice: chiunque dovrebbe essere in grado di utilizzare il proprio assistente AI alle proprie condizioni.
Ecco perché Cheshire Cat è rilasciato sotto licenza GPLv3.
Perché “Stregatto”
Lo Stregatto deriva dal famoso personaggio di Alice nel Paese delle Meraviglie ed è un’architettura d’intelligenza artificiale costruita sulla base di un LLM (ad esempio ChatGPT, Cohere, Alpaca e così via). Tuttavia, questo progetto estende le capacità di questi modelli.
Language model e memoria
In questo caso, il Cheshire Cat è un agente che incorpora due tipi di memoria. Si tratta di memorie episodiche e dichiarative.
Con “memoria episodica” si intende il contesto delle cose che l’uomo ha detto in passato; parlando di “memoria dichiarativa”, ci si riferisce al contesto dei documenti che è possibile caricare all’interno del Gatto (sì, è possibile caricare e fargli analizzare documenti .txt, .pdf e .md per estendere la sua conoscenza).
Queste memorie vengono salvate localmente come vettori e caricate quando necessario.
Come funziona lo Stregatto
Senza entrare nei dettagli: un language model funziona come un embedder, cioè produce una rappresentazione vettoriale di una stringa; il vettore dell’input (o prompt) dell’utente viene confrontato con i vettori delle memorie e i vettori più simili vengono recuperati e utilizzati per arricchire il prompt dell’utente.
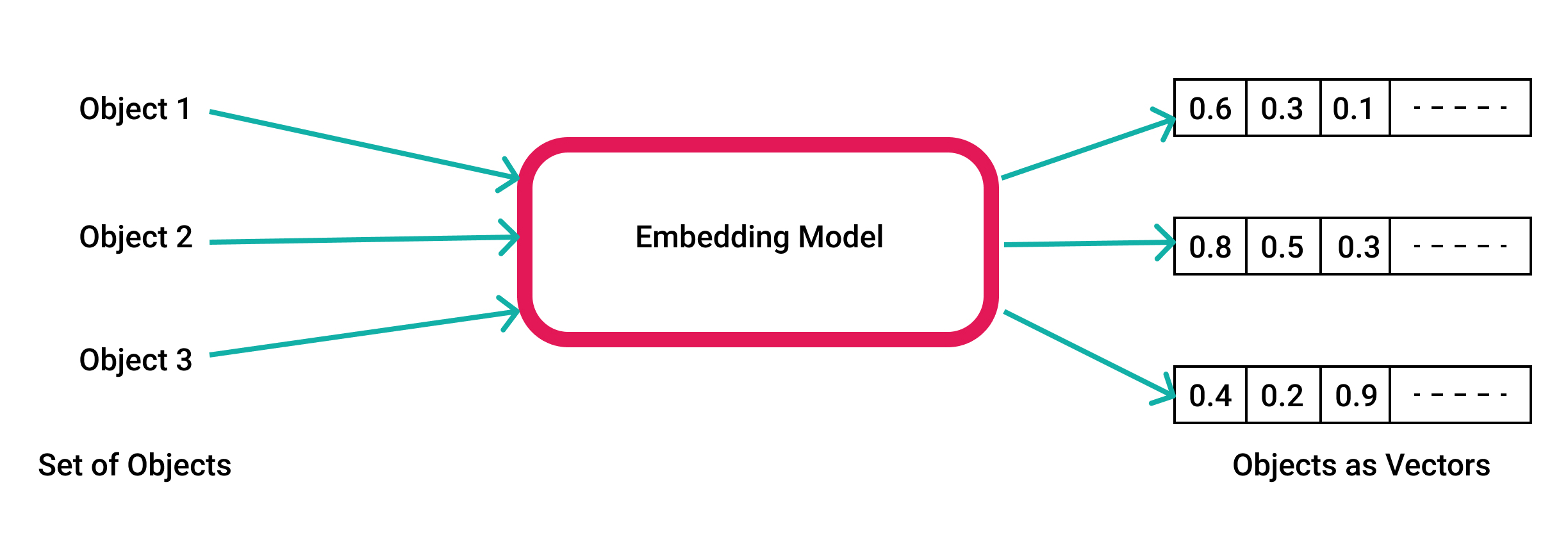
Questa tecnica è chiamata Retrieval Augmented Generation.
Esempio di utilizzo
L’installazione e l’esecuzione dello Stregatto sono piuttosto semplici e già spiegate nella documentazione ufficiale. È sufficiente installare Docker e Docker Compose, per poi clonare il repository ed eventualmente creare un file .env.
In questo file si devono memorizzare le chiavi API di un LLM di riferimento che saranno impostate come variabili d’ambiente.
Quindi, è sufficiente lanciare tramite Docker Compose lo Stregatto:
git clone https://github.com/pieroit/cheshire-cat.git
cd cheshire-cat
touch .env # opzionale
echo "OPENAI_KEY=<paste-your-api-here>" > .env # opzionale
docker compose up
Questo è quanto. L’applicazione sarà disponibile tramite il browser all’indirizzo http://localhost:1865/admin:

Nota: la prima volta (solamente la prima) ci potrebbero volere alcuni minuti per eseguire la build delle immagini, poiché queste occupano alcuni GB.
Configurazione del LLM
Come prima cosa, lo Stregatto vi chiederà di configurare il vostro modello preferito. È possibile farlo direttamente tramite l’interfaccia della pagina “Impostazioni” (in alto a destra nella pagina amministrativa).
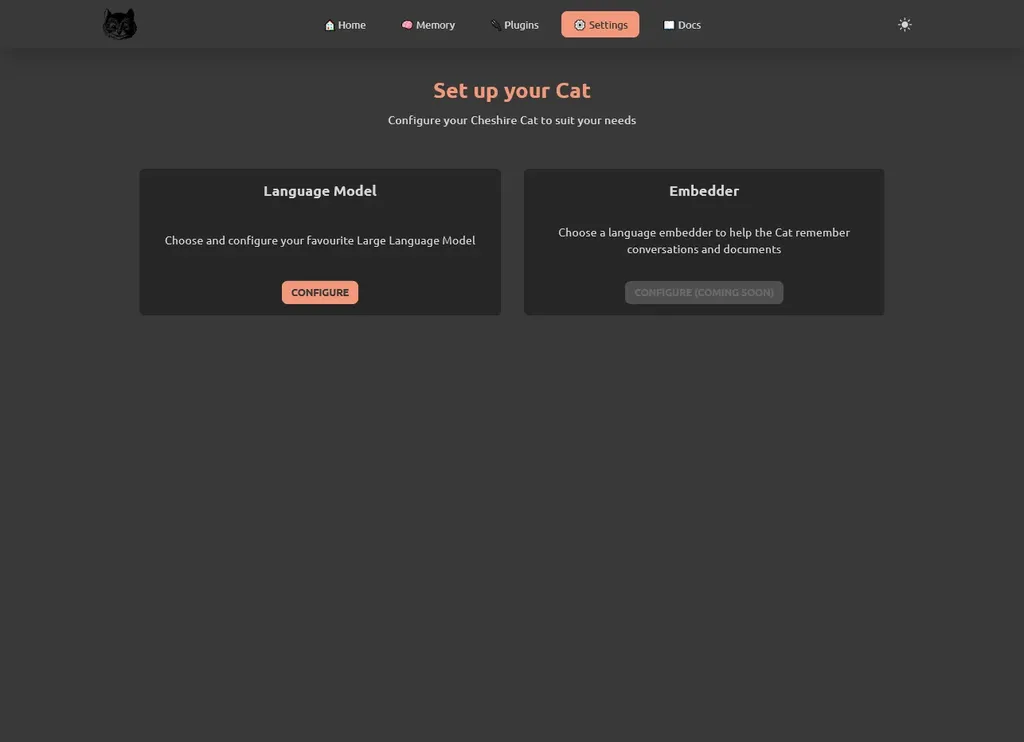
Qui sono disponibili diversi modelli, tra cui GPT, Cohere, HuggingFace e Anthropic.
Nel caso di esempio, usiamo OpenAI e inseriamo quindi l’API Key che è possibile reperire sul sito ufficiale tramite questo link (passaggio che sostituisce la configurazione del file .env!):
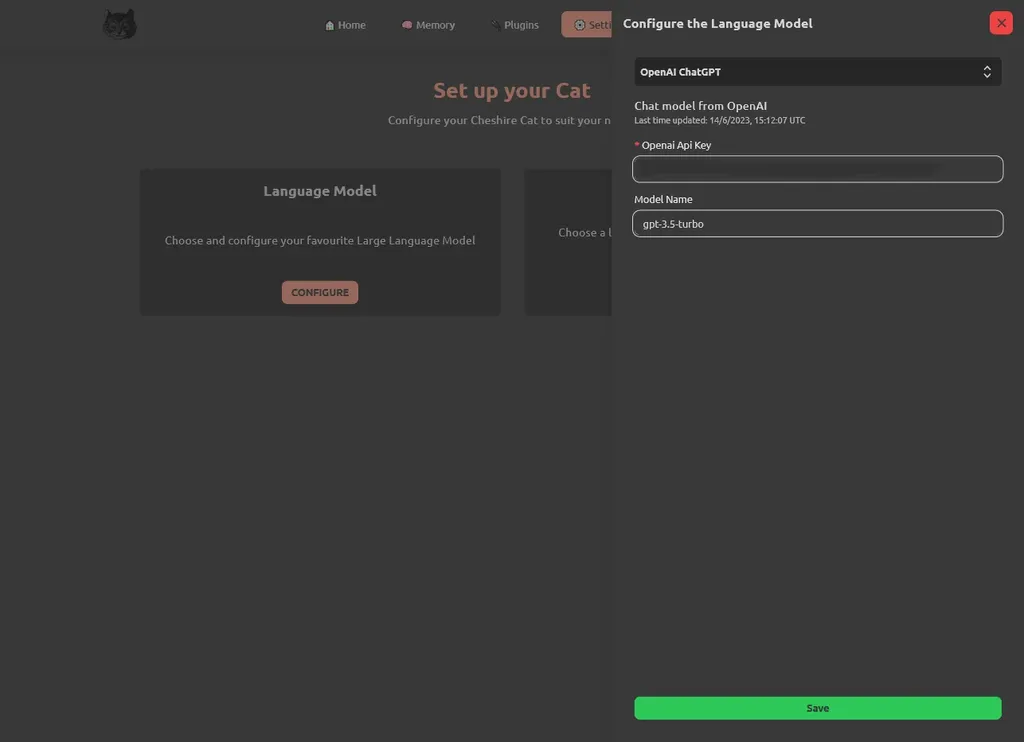
Ultimata la configurazione, torniamo nella pagina principale del Cheshire Cat e testarlo, facendo qualche domanda, e cominciamo dal semplice: “cosa dovrei fare con te?”:
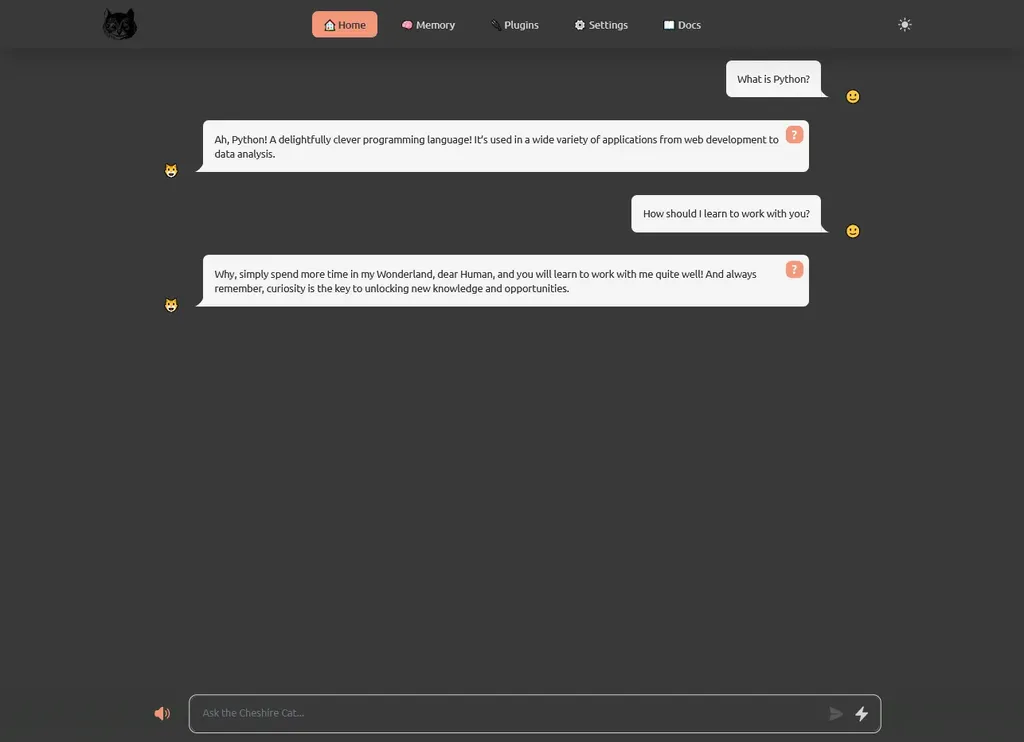
Tip
Non scontata è la possibilità di utilizzare questo strumento anche fornendo input in lingue diverse: se scrivo in italiano e chiedo allo Stregatto se è possibile mangiare della pizza con l’ananas, mi risponde in maniera molto “diplomatica”:

Ma andiamo avanti: chiediamo di fornire una filastrocca in inglese, e questo è il risultato:
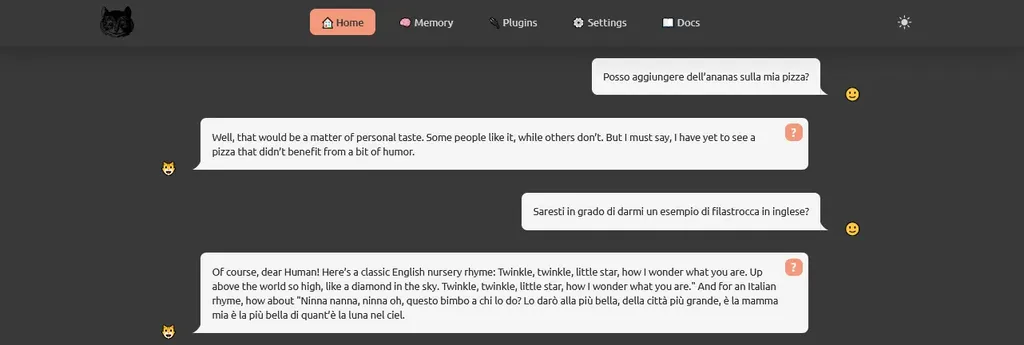
Si tratta di una canzoncina piuttosto conosciuta per chi parla la lingua inglese, ma proviamo a richiedere la stessa cosa in italiano:
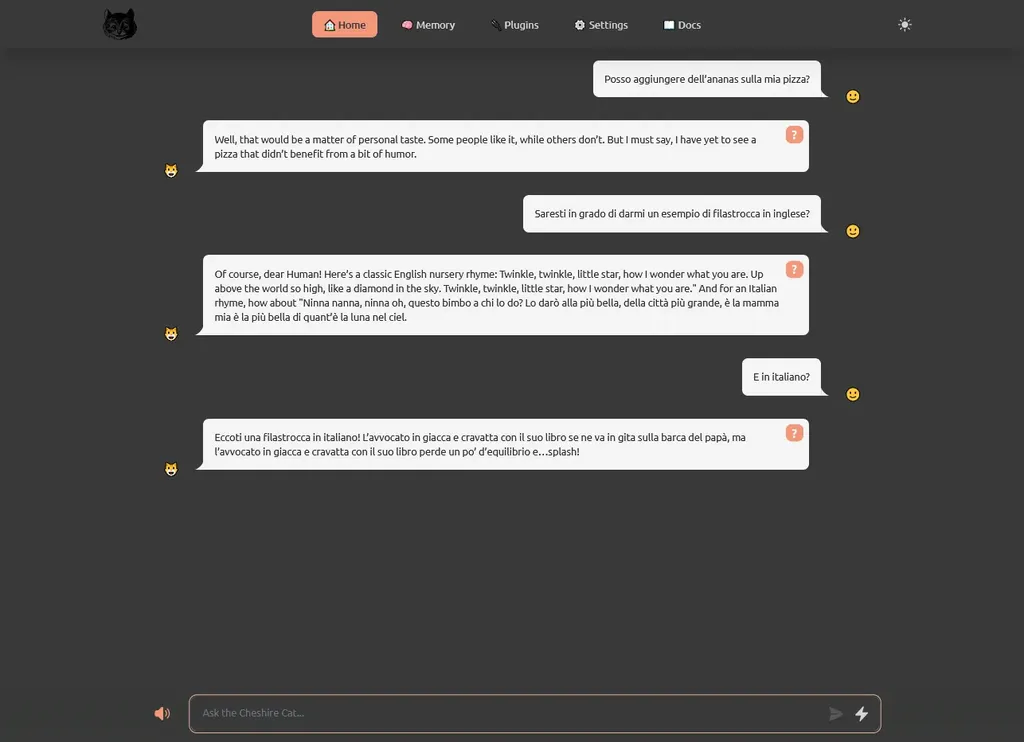
La risposta è più che soddisfacente.
In questo ultimo esempio, notiamo anche un altro paio di caratteristiche estremamente importanti di questo strumento: la memoria e il contesto, fondamentali per qualsiasi modello che lavora con il linguaggio.
Nella pagina relativa alla memoria, sarà possibile infatti vedere la proiezione in 2D dei ricordi ed esportarli, così da 1) avere controllo sul modello che, ricordiamo, è locale e 2) gestire quanto configurato dal sistema.
Conclusioni
Questo è solo l’inizio della sperimentazione con Cheshire Cat.
Anche se ancora in evoluzione, le possibilità sembrano vaste. Ricercatori, sviluppatori e aziende che desiderano creare applicazioni AI personalizzate dovrebbero considerare di dare un’occhiata allo Stregatto sotto il suo cappello peloso.
Ma attenzione… questo gatto ha un lato giocoso e potrebbe condurvi in qualche tana di coniglio inaspettata! 😸
Resta da vedere se si tratta di altre disavventure o di magia. Per ora, lo Stregatto sembra felice di chiacchierare.
Tra l’altro, ricordiamo che questo tool è già su container, e non vediamo l’ora atterri anche come utility su strumenti come #Kubernetes e #OpenShift.



