GAN ed healthcare

GAN ed healthcare: le reti generative avversarie potrebbero sembrare un gioco da ragazzi: in che modo possono però essere costituire un vantaggio enorme se utilizzate in determinati settori, come in ambito sanitario?
Introduzione
Negli Stati Uniti, a partire dal 2009, con la promulgazione dell’HITECH Act, vengono stanziati 30 milioni in dollari di incentivi per tutte quelle strutture sanitarie che adottassero sistemi che fruissero di cartelle cliniche elettroniche (in inglese, EHR, che sta per Electronic Health Record).
Questo vuol dire che il passaggio dalle consuete cartelle cartacee ad un sistema completamente digitalizzato che contenesse le informazioni circa la salute dei cittadini prese piedi e nel giro di pochi anni è diventato la consuetudine.
Infatti, uno studio condotto nel 2016 dall’ONC (aka Office of the National Coordinator for Health Information) ha stimato che il 95% degli ospedali americani ha adottato questo approccio. Non male, no?
L’utilizzo di queste tecnologie non porta un beneficio solo in termini di durabilità, consistenza e reperibilità delle informazioni, ma queste informazioni hanno portato anche enormi vantaggi per chi quei dati sa sfruttarli: negli ultimi anni abbiamo infatti assistito ad un boom di studi sugli effetti dei Big Data, e gli effetti nel settore healthcare non sono da meno.
Avere a disposizione grandi quantità di dati su referti medici, immagini di radiografie e via dicendo, ha permesso di portare a compimento l’implementazione di diversi strumenti di diagnostica predittiva, che nel passato utilizzava le reti neurali convoluzionali.
Questo tipo di rete convoluzionale ha un enorme successo nel momento in cui gli esempi a sua disposizione contengono tanti dati “positivi” quanti “negativi”, per ognuna delle classi che è necessario stimare.
In questo senso, le reti convoluzionali sono perfette per il riconoscimento di oggetti tramite immagini: insegnare ad un sistema a distinguere un gatto da un cane o da un’auto è piuttosto semplice, anche se non sempre è efficace nel caso dei volti umani (leggi l’articolo Coded Bias).
Il primo problema si presenta dunque nel momento in cui non sia una “parità” di esempi a disposizione: avere un dataset di buona qualità e quantità è merce rara. Non solo: un problema rilevante è rappresentato dall’anonimizzazione dei dati: i più complottisti potrebbero dire che “usare questi dati compromette la privacy dei pazienti o dell’intera popolazione”.
In effetti, il problema del rendere non identificabili informazioni di questo genere non è una questione così irrilevante: si parla pur sempre di dati estremamente sensibili, che possono e devono essere utilizzati a scopo benefico, ma senza mai compromettere la privacy della fonte originaria.
In questo senso, le reti generative avversarie sono perfette, soprattutto per un settore come quello dell’healthcare: vediamo il perché.
Cos’è una rete neurale convoluzionale
Una rete neurale convoluzionale (spesso abbreviata in ConvNet o CNN) è un algoritmo di deep learning che può prendere in input un’immagine, assegnare un fattore di rilevanza in termini di pesi e bias a vari aspetti/oggetti nell’immagine ed essere in grado di apprendere a riconoscere, ad esempio, oggetti in un’immagine.
La pre-elaborazione richiesta in una rete di questo tipo è molto più bassa rispetto ad altri algoritmi di classificazione, per cui mentre nei metodi primitivi i filtri sono progettati manualmente, con un addestramento sufficiente, questa rete ha la capacità di apprendere in maniera semi-autonoma a migliorarsi.
L’architettura di una rete come questa è analoga a quella del modello utilizzato dal cervello per gestire la connettività dei neuroni ed è stata ispirata dall’organizzazione della corteccia visiva. I singoli neuroni rispondono agli stimoli solo in una regione ristretta del campo visivo nota come campo recettivo.
Come funziona una rete neurale convoluzionale
Questo tipo di rete è costituita da più livelli, ognuno dei quali è specializzato in un’attività diversa: allo stesso modo funziona il cervello umano, perché questo opera delle semplificazioni che ci permette di riconoscere gli oggetti applicando diverse “funzioni”.
Se dovessimo rappresentarla in modo semplice, questo potrebbe essere uno schema: fornendo un input alla rete, questo passa attraverso diverse “convoluzioni”, viene partizionato e i risultati forniti dai diversi livelli vengono poi assemblati per produrre il risultato finale.
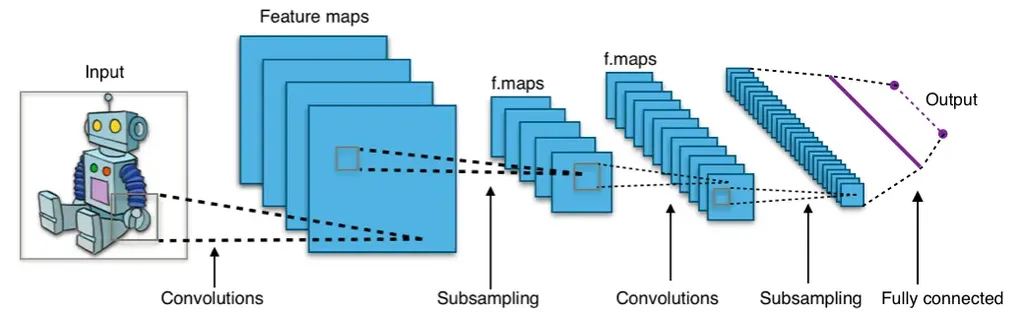 Esempio di CCN - Credits to Wikimedia
Esempio di CCN - Credits to Wikimedia
Che vuol dire convoluzione? Vuol dire che questo strato calcola l’output dei neuroni che sono collegati a regioni locali o campi recettivi nell’input, calcolando un prodotto scalare tra i loro pesi e un piccolo campo recettivo a cui sono collegati nel volume di input; in altre parole, ogni calcolo porta all’estrazione di una mappa delle caratteristiche dell’immagine di input.
Immagina di avere un disegno rappresentato come una matrice di valori 5x5, e prendi una matrice 3x3 e fai scorrere quella finestra 3x3 attorno all’immagine.
In ogni posizione di quella matrice, moltiplichi i valori della tua finestra 3x3 per i valori nell’immagine che sono attualmente coperti dalla finestra; di conseguenza, otterrai un singolo numero che rappresenta tutti i valori in quella finestra delle immagini.
Utilizzi questo livello per filtrare: mentre la finestra si sposta sull’immagine, controlli i modelli in quella sezione dell’immagine.
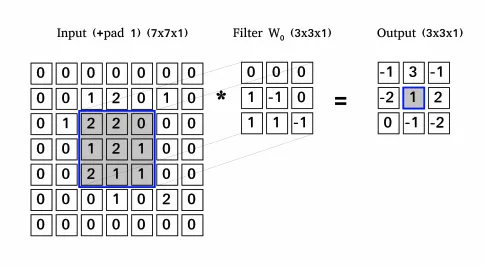 Credits to: https://www.cosmos.esa.int/web/machine-learning-group/convolutional-neural-networks-introduction
Credits to: https://www.cosmos.esa.int/web/machine-learning-group/convolutional-neural-networks-introduction
Funziona grazie ai filtri, che vengono moltiplicati per i valori emessi dalla convoluzione. Il suo compito principale è dunque quello di individuare degli schemi con una tale precisione che semplificare porti a generalizzare il modello (per approfondire queste tematiche, vedi le risorse utili in fondo).
Cos’è una rete generativa avversaria
Le reti generative avversarie (abbreviate in GAN) sono un insieme di modelli di reti neurali profonde, sviluppate da Ian Goodfellow nel 2014, utilizzate per produrre dati sintetici.
Vi immaginate? Produrre dei dati che fossero verosimili, ma non simili, rilevanti per una situazione specifica, ma che non provengono dal mondo reale.
L’obiettivo di una GAN è quindi quello di addestrare un discriminatore ad essere in grado di distinguere tra dati reali e falsi e allo stesso tempo addestrare un generatore a produrre istanze sintetiche di dati che possono ingannare in modo affidabile il discriminatore.
Il discriminatore è una normale rete neurale convoluzionale utilizzata per distinguere tra immagini autentiche e sintetiche e il generatore è una rete neurale convoluzionale modificata e addestrata per produrre immagini false dall’aspetto autentico.
Le GAN addestrano allo stesso modo sia il discriminatore che il generatore per migliorare tramite un approccio iterativo la capacità del discriminatore di individuare immagini false e la capacità del generatore di produrre immagini realistiche, creando una sorta di “battaglia” intestina che però porta benefici progressivi.
Come funziona una rete generativa avversaria (o GAN)
Nella figura seguente, vediamo come le zebre diventino improvvisamente identiche a dei cavalli, anche se appare chiaro che ad un occhio attento le strisce sui corpi dei cavalli siano comunque visibili: questa sorta di “rumore” permette però alla rete di calibrarsi rispetto ad eventuali immagini “false” e lo rende sempre più prestante.
 Zebre vs. cavalli: distinguere i veri dai falsi
Zebre vs. cavalli: distinguere i veri dai falsi
Cosa succederebbe se facessimo lo stesso utilizzando delle TAC al cervello? Nell’illustrazione seguente, un generatore viene addestrato inserendo dei pixel di rumore casuali e quindi generando immagini cerebrali false. Le immagini false create dal generatore vengono quindi inserite nel discriminatore insieme alle immagini reali, per cui quest’ultimo dovrà imparare a distinguere tra immagini reali e false.
La formazione del generatore mira a produrre immagini false sempre più realistiche che possano ingannare il discriminatore. Man mano che l’addestramento continua, il generatore migliora nel produrre falsi e il discriminatore migliora nel distinguere tra immagini reali e false finché il generatore non produce immagini che assomigliano molto alle immagini autentiche.
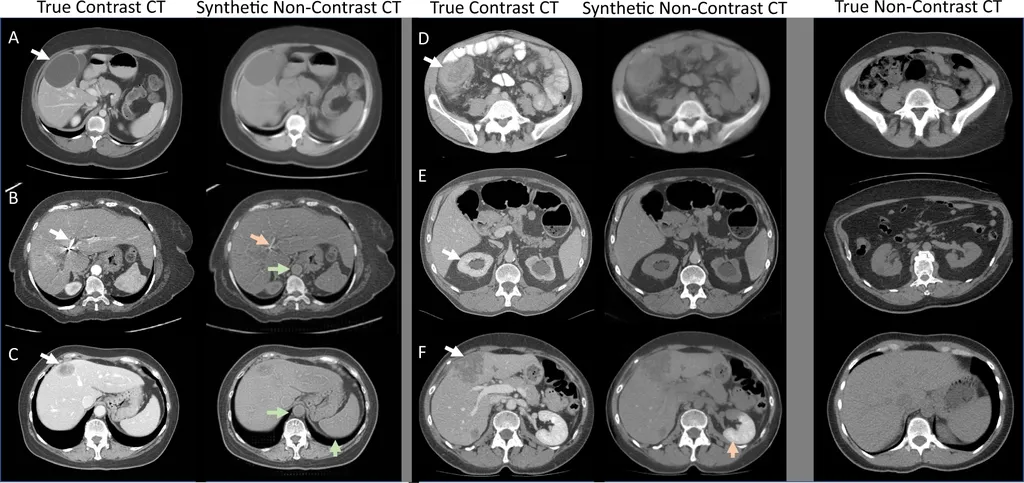 Esempio di GAN applicate
alle immagini di TAC
Esempio di GAN applicate
alle immagini di TAC
Una volta completato l’addestramento, la GAN dovrebbe essere in grado di produrre immagini realistiche che possono essere utilizzate per aumentare i dati esistenti o creare set di dati completamente nuovi (primo scopo, quindi, la produzione di dati sintetici), nonché a riconoscere correttamente quali sono quelle false da quelle vere.
Benefici
Questa tipologia di rete è utile in questi casi perché possono imparare a produrre falsi esempi dei dati sottorappresentati, addestrando meglio il modello. Oltre a migliorare il rilevamento delle malattie, le GAN possono essere utilizzati per l’anonimizzazione dei dati, che impedisce l’esposizione delle informazioni personali del paziente.
La normativa sulla privacy dell’Health Insurance Portability and Accountability Act del 1996 (HIPAA) impone infatti la protezione delle informazioni del paziente, il che significa che lavorare con questi dati non è uno scherzo.
Vale a dire, la maggior parte dei metodi attuali di anonimizzazione può essere invertita con un po’ di reverse engineering, compromettendo la privacy dei dati personali dei pazienti. In questo senso, le reti avversarie, sia nella ricerca che nella pratica, rappresentano una soluzione promettente a molti dei problemi spinosi che devono affrontare oggi l’assistenza sanitaria.
Oltre all’anonimizzazione infatti, abbiamo detto che spesso un problema è rappresentato dalla scarsità di informazioni a nostra disposizione per l’addestramento, soprattutto se si tratta di avere un dataset sufficiente per avere dei casi reali e dei controesempi: in questo senso, una rete GAN mette a disposizione a termini del suo addestramento un dataset perfetto perché completamente anonimo, ma “veritiero”.
Non a caso, le applicazioni più diffuse dei GAN nel settore sanitario riguardano l’imaging medico. Due importanti attività di imaging medico sono la segmentazione dei dati per i tumori cerebrali e la sintesi di immagini mediche.
Nel primo caso, si tratta di suddividere le TAC del cervello in singole immagini che identifichino i bordi del tumore, il tessuto sano o anche interi siti di tumore. Sebbene la rilevazione della maggior parte dei tipi di tumore cerebrale sia in genere semplice per un medico, la definizione del confine del tumore mediante la valutazione visiva rimane una sfida.
Come detto in precedenza, un’altra interessante applicazione dei GAN è nella sintesi di immagini mediche. I dati di imaging medico sono raramente disponibili per analisi su larga scala a causa dell’alto costo per ottenere annotazioni cliniche.
Dato questo fattore che costituisce un blocco vero e proprio, molti progetti di ricerca hanno lavorato per sviluppare metodi affidabili per la sintesi di immagini mediche.
Queste immagini false possono essere utilizzate per aumentare i dati in situazioni in cui il numero di immagini retiniche è limitato e possono essere ulteriormente utilizzate per addestrare futuri modelli di intelligenza artificiale.
In futuro, questi metodi possono essere utilizzati per produrre dati per modelli di addestramento per rilevare malattie in cui non ci sono abbastanza dati reali per addestrare un modello accurato. Inoltre, questo tipo di dati di imaging sintetici può essere utilizzato per proteggere ulteriormente la privacy del paziente.
In questo senso, è chiaro che le GAN si siano dimostrate promettenti nello spazio della segmentazione delle immagini e della sintesi: hanno dunque tutto il potenziale per rivoluzionare l’analisi sanitaria.
Il metodo di segmentazione dell’immagine in medicina può essere esteso all’identificazione di oggetti estranei nelle immagini mediche, al rilevamento di ulteriori tipi di escrescenze tumorali e all’identificazione precisa della struttura dell’organo.
Inoltre, possono essere davvero un beneficio a costi ridottissimi nell’ambito della sintesi di immagini mediche. Nella maggior parte dei casi, l’analisi delle immagini mediche è limitata dalla mancanza di dati e/o dal costo elevato dei dati autentici.
Così facendo, si potrebbe fornire uno strumento fondamentale a ricercatori e medici per lavorare con immagini sintetiche ma realistiche e di alta qualità. Ciò potrebbe migliorare significativamente la diagnosi, la prognosi e l’analisi della malattia, portando benefici quindi su tutti i fronti nell’ambito sanitario.
Articoli Correlati








