IA generativa: a che punto siamo

L’IA generativa ad oggi rappresenta l’innovazione tecnologica più dirompente dall’avvento del personal computer e dalla nascita di 5 Internet, con il suo enorme potenziale: questa branca dell’intelligenza artificiale permette di creare immagini attraverso della grafica computerizzata, ma anche simil-fotografie, montaggi video, campagne pubblicitarie e sì, anche articoli.
La generazione d’immagini è un campo relativamente nuovo: ne abbiamo parlato in questo articolo.
Sebbene l’IA generativa sia stata un’area di ricerca sull’IA fin dal 2014, è decollata nella seconda metà del 2022 quando la tecnologia è stata messa nelle mani dei consumatori con il rilascio di diversi servizi di modelli da testo a immagine come MidJourney, Dall-E 2, Imagen e il rilascio open-source del famoso progetto di Stability AI’s, Stable Diffusion.

Immagine generata da StableDiffusion che rappresenta un alieno
A questo ha fatto rapidamente seguito ChatGPT di OpenAI, che ha ipnotizzato i consumatori con una versione di GPT-3 (ora in versione potenziata) addestrata al dialogo conversazionale che apparentemente aveva una risposta per tutto e forniva risposte in modo molto simile a quello umano.
Allo stesso tempo, i VC alla ricerca di una nuova tecnologia su cui investire hanno colto l’opportunità di strumenti di IA generativa e sia Stability AI che Jasper sono diventate immediatamente degli unicorni con finanziamenti di serie A superiori a 100 milioni di dollari. Anche Copilot di GitHub ha visto un’ampia adozione, uno strumento costruito sul Codex di Open AI che è stato addestrato su tutti i repository di codice pubblico di Github e assiste le persone che sviluppano con strumenti come i suggerimenti a base di testo in linguaggio naturale che viene trasformato in codice software eseguibile.
Esempio di utilizzo di GitHub Copilot
Tuttavia, ci sono stati notevoli contraccolpi contro l’IA generativa. Sono state sollevate molte preoccupazioni in merito a possibili violazioni del copyright per ciò che concerne l’arte, il testo e il codice sorgente prodotto dall’IA generativa, anche rispetto all’impatto sui posti di lavoro dei creativi. L’azione legale collettiva intentata contro Microsoft per Copilot costituirà un prezioso precedente nei tribunali per il quale potrebbero essere intentate altre cause, poiché molti sviluppatori sostengono che la loro proprietà intellettuale sia stata rubata. Chi lavora nell’arte ma anche nello sviluppo, vuole che le proprie opere siano escluse dallo scraping su larga scala effettuato per creare insiemi di dati validi per i modelli linguistici e d’immagini di grandi dimensioni: un esempio sono gli artisti di ArtStation si sono ribellati chiedendo che tutta l’arte generata dall’IA sia bandita dalla piattaforma.
L’IA generativa è un’area di ricerca attiva fin dagli anni ‘60, quando Joseph Weizenbaum sviluppò il primo chatbot chiamato ELIZA. Si trattava di uno dei primi esempi di elaborazione del linguaggio naturale (NLP) ed era stato progettato per simulare le conversazioni tra uno psicoterapeuta e un utente, generando risposte in base al testo ricevuto. Sebbene si trattasse di un’implementazione primitiva basata su regole e volta a sintetizzare una conversazione umana, il sistema ha aperto la strada a ulteriori sviluppi nei decenni successivi nel campo dell’NLP.
La moderna IA generativa si basa sulla più nota branca del deep learning, le cui origini risalgono agli anni Cinquanta. Le innovazioni nel campo di questa area dell’intelligenza artificiale sono rimaste in sordina per decenni, per poi risorgere negli anni ‘80 e ‘90 con l’avvento delle reti neurali artificiali (abbreviate in RNA) e degli algoritmi di retropropagazione.
Negli anni 2000 e 2010 la quantità di dati disponibili e le capacità di calcolo sono migliorate al punto da rendere pratico il deep learning. Nel 2012 Geoffrey Hinton (noto come padrino del deep learning) e il suo team hanno fatto un passo avanti nel campo del riconoscimento vocale utilizzando le reti neurali convoluzionali (abbreviate in CNN) e nel 2014 hanno fatto un passo avanti analogo nel campo della classificazione delle immagini, aprendo la strada a importanti innovazioni successive nello studio dell’intelligenza artificiale.
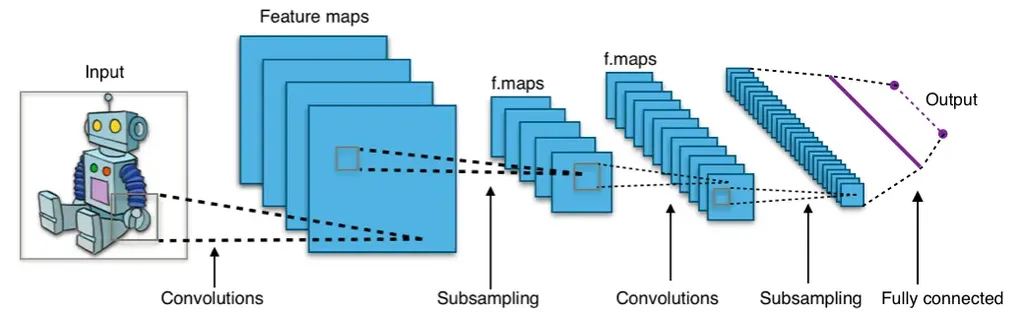 Esempio di CCN - Credits to Wikimedia
Esempio di CCN - Credits to Wikimedia
Nel 2014 Ian Goodfellow ha pubblicato il suo articolo fondamentale sulle Reti Generative Avversarie (GAN), che metteva due reti l’una contro l’altra in un gioco a somma zero (se uno vince, l’altro perde: come nel poker) per creare nuove immagini che fossero simili nell’aspetto alle immagini su cui il modello era stato addestrato, ma non uguali.

Zebre vs. cavalli: distinguere i veri dai falsi
Questo lavoro ha portato a sviluppi incrementali dell’architettura GAN che hanno dato risultati sempre migliori nella sintesi di immagini negli anni successivi, e gli stessi metodi hanno iniziato a essere applicati a nuove applicazioni come la composizione musicale. Sono state sviluppate nuove architetture di modelli sotto forma di reti neurali convoluzionali e ricorrenti (per generazione di testi e video), memorie a breve termine (LSTM) (generazione di testi), trasformers (sempre per generazione di testi) e modelli di diffusione (generazione d’immagini).
Sebbene negli ultimi anni siano stati raggiunti risultati significativi in questo settore, tra cui la generazione d’ immagini fotorealistiche, video deepfake (dove chi parla, è il risultato di un montaggio sintetico) e anche sintesi audio di voci reali perfettamente credibili, è stato solo nella seconda metà del 2022 che sono stati rilasciati alcuni servizi d’immagini basati sul concetto di diffusione: (MidJourney, Dall-E 2, Stable Diffusion) sono alcuni, ma c’è stato anche, insieme al rilascio di ChatGPT di OpenAI, dei modelli di diffusione di text-to-video (per esempio Make-a-Video) e text-to-3D (come DreamFusion, Magic3D e Get3D), di cui i media hanno preso nota.
Con questi pochi esempi, abbiamo visto come l’impatto dell’IA generativa sarà senza dubbio un argomento importante nel 2023. I casi d’uso della generazione d’immagini, testi, codici, audio, musica, video e modelli 3D che abbiamo visto fino a ora sono solo la punta dell’iceberg: nel 2023 arriveranno sicuramente altri casi di utilizzo che rappresenteranno più o meno delle innovazioni, insieme sicuramente al consolidato timore associato alla possibile perdita di posti di lavoro per chi fa attività creative: sarà davvero così, o nasceranno invece nuovi mestieri?



