Retrieval-Augmented Generation e LLM: cosa cambia

RAG sta per Retrieval-Augmented Generation, quindi un modello di generazione aumentata tramite delle attività di retrieval… Ok, facciamo un passo indietro e parliamo solo della parte “generativa” per un minuto, dimenticando il resto.
La generazione si riferisce ai modelli linguistici di grandi dimensioni, o LLM, che generano testo in risposta a una richiesta dell’utente, detta prompt.
Questi modelli possono avere un comportamento indesiderato e possiamo raccontarlo tramite un esempio molto banale. Immaginate di parlare con un bambino che pone questa domanda: “Nel nostro sistema solare, quale pianeta ha più lune?”
La mia risposta potrebbe essere: “Giove ha 88 lune”. Ora, in realtà, ci sono un paio di cose che non vanno: innanzitutto, non ho alcuna fonte (solo ricordi) a sostegno di ciò che sto dicendo. Quindi, anche se ho detto con sicurezza “So la risposta!”, non ho una fonte certa, e inoltre la mia risposta non è aggiornata.
Quindi abbiamo due problemi: uno è l’assenza di fonti, mentre il secondo problema è che non sono aggiornata. Questi sono due comportamenti che vengono spesso considerati problematici quando si interagisce con modelli linguistici di grandi dimensioni e sono sfide ben note per i LLM.
Ora, cosa sarebbe successo se avessi cercato la risposta su una fonte affidabile come il sito della NASA?
Beh, allora sarei stata in grado di dire: “Ah, ok! Quindi la risposta è Saturno con 146 lune”, e in effetti la risposta attuale è questa, ma continua a cambiare perché chi si occupa di questo campo continua a scoprire sempre più lune. Se non altro, avrei avuto una risposta su qualcosa di più credibile, e proveniente da una fonte autorevole.
Bene, cosa c’entra questo con i modelli linguistici di grandi dimensioni? Come avrebbe risposto a questa domanda un modello linguistico di grandi dimensioni?
Supponiamo che un utente ponga la stessa domanda. Un modello linguistico di grandi dimensioni direbbe con sicurezza: “Sono stato addestrato e, in base ai parametri che conosco durante l’addestramento, la risposta è Giove”.
La risposta è sbagliata, ma magari non lo sappiamo, anche se il modello linguistico di grandi dimensioni è molto sicuro di ciò che ha risposto.
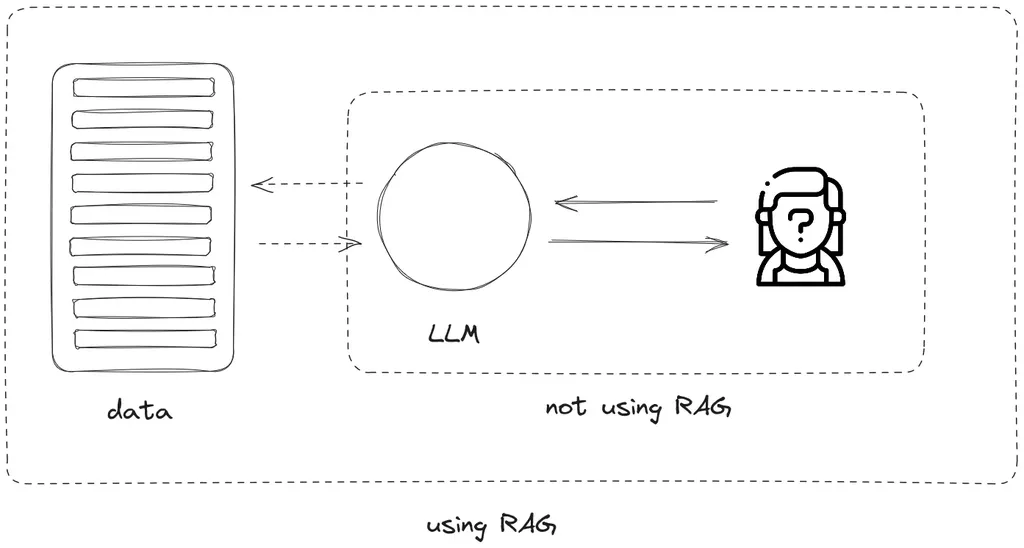
Ora, cosa succede quando si aggiunge questa parte di “recupero” che “aumenta” l’informazione? Che cosa significa?
Significa che ora, invece di fare affidamento solo su ciò che il LLM conosce attualmente, aggiungiamo un archivio di contenuti aggiornati. Questo può avvenire tramite Internet, o tramite una raccolta di documenti o fonti offline.
Il punto, però, è che il modello per prima cosa va a controllare l’archivio di contenuti e dice: “Ehi, puoi recuperare per me le informazioni che sono rilevanti per la richiesta dell’utente?”. In questo caso, si ottiene una risposta potenziata dal contenuto di dati aggiornati, e -probabilmente- più corretta. Come ti sembra?
In origine, se stiamo parlando con un modello generativo, questo dice: “Oh, ok, conosco la risposta. Eccola”. Ma ora, utilizzando il framework RAG, il modello generativo ha un’istruzione che dice: “Per prima cosa, vai a recuperare i contenuti rilevanti, combinali con la domanda dell’utente e solo dopo genera la risposta”.
Quindi, in che modo RAG aiuta le due sfide del LLM che ho menzionato prima?
Prima di tutto, comincerò con la parte obsoleta: ora, invece di dover rivedere il modello, se si presentano nuove informazioni, tutto ciò che si deve fare è aumentare l’archivio dati con nuove informazioni, aggiornandole. In questo modo, la prossima volta che un utente porrà la domanda, avremo delle informazioni di prima mano.
Il secondo problema, la fonte: i modelli linguistici di grandi dimensioni sono ora istruiti a prestare attenzione ai dati della fonte primaria prima di fornire la propria risposta, mentre ora sono in grado di fornire prove.
In questo modo è meno probabile che abbia allucinazioni o che fornisca informazioni non corrette, perché è meno probabile che si affidi solo ai dati appresi durante l’addestramento.
Questo permette anche di far sì che il modello abbia un comportamento che può essere molto positivo, ovvero sapere quando è il caso di dire “Non lo so”. Se infatti non è possibile rispondere in modo affidabile alla domanda dell’utente sulla base dell’archivio di dati, il modello dovrebbe dire “Non lo so”, invece di inventare qualcosa di credibile che potrebbe fuorviare l’utente.
Questo però può avere anche un effetto negativo, perché se la sorgente dati (ossia il retriver di informazioni) non ha una qualità sufficiente da fornire al modello linguistico di grandi dimensioni le informazioni di base “migliori”, allora forse la domanda dell’utente che può ricevere una risposta non ottiene una risposta.
Ed è qui che molte grandi aziende stanno lavorando: migliorare il retriever, in modo da fornire al modello i dati di migliore qualità su cui basare la propria risposta, in modo che il LLM possa dare la risposta più ricca all’utente quando genera la risposta.
E tu, l’hai provato?
Risorse utili

Articoli Correlati