NLP e Machine Learning

Nell’analisi del linguaggio naturale vengono impiegati di frequente diversi algoritmi di machine learning. Quali sono quelli più comuni? Quali le differenze e gli utilizzi?
Vediamo in questo post una breve introduzione al mondo dell’analisi del linguaggio naturale e Machine Learning!
Algoritmi di machine learning
Gli algoritmi di machine learning normalmente appartengono a tre grandi “famiglie”: esistono quelli che eseguono attività di classificazione, di regressione e infine di clustering.
Quelli maggiormente utilizzati per l’analisi dei testi sono ad esempio le reti neurali, gli alberi decisionali, le macchine a vettori di supporto, K-Means e K-NN.
Ognuno di questi appartiene ad una famiglia diversa: K-Means, per esempio, è un algoritmo di clustering, quindi permettono di raggruppare diversi dati che nono stati precedentemente “etichettati”.
Questa tipologia di algoritmo permette di definire delle strategie di marketing che analizzino un certo target di clienti e la sua evoluzione, come avviene all’interno del processo di segmentazione.
K-NN permette invece di calcolare la similarità e quindi la distanza tra due vettori, come possono essere due array di testi, e appartiene agli algoritmi di classificazione.
I metodi di classificazione hanno come scopo quello di etichettare e quindi assegnare una o più parole chiave ad un documento, come avviene in un filtro spam.
In ambito data mining e text mining ci sono diverse attività che possiamo assolvere con l’ausilio di algoritmi di machine learning: ad esempio, categorizzare dei testi, identificare un autore, identificare la lingua utilizzata nel testo o analizzare il sentiment.
Ma qual è la differenza tra questi due campi?
Text Mining vs Data Mining
Spesso si ha l’impressione che queste due tipologie di attività coincidano: la realtà è che il primo spesso opera con dati non strutturati, che quindi richiedono degli step in più non essendo elaborati, mentre il secondo si occupa di estrarre i dati da diverse fonti.
Il data mining è invece il processo di ricerca di modelli ed estrazione di dati utili da grandi set di dati.
Questo campo è utilizzato per convertire dati grezzi in dati utili.
Il data mining può essere estremamente utile per migliorare le strategie di marketing di un’azienda poiché con l’aiuto di dati strutturati possiamo studiare i dati da diversi database e quindi ottenere idee e strategie che ci permettano di aumentare la produttività di un’azienda.
Il text mining in particolare è un campo multi-disciplinare che coinvolge diverse branche e che porta a diverse tipologie di attività: ad esempio, al suo interno esistono delle macro-categorie come l’information retrieval, l’information extraction e soprattutto il natural language processing.
Il text mining è una branca del data mining e prevede quindi l’elaborazione dei dati da vari documenti di testo.
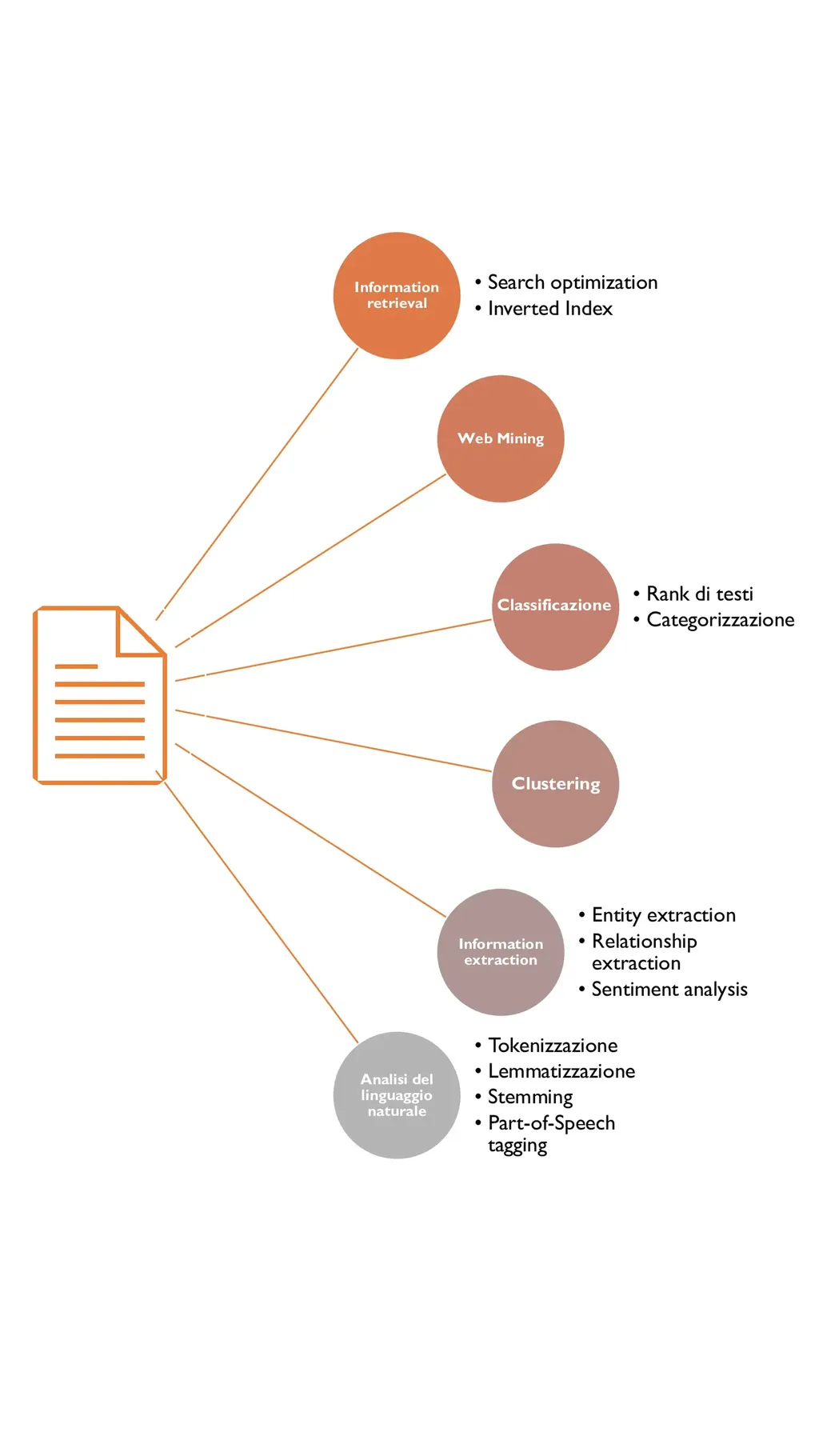 Attività dell’Information retrieval
Attività dell’Information retrieval
NLP e Machine Learning
Come visibile nella figura precedente, nell’ambito del text mining abbiamo la branca del natural language processing: le tecniche utilizzate sono normalmente analisi lessicale, sintattica e semantica.
In generale, questa tecnica, si focalizza sul concetto di bag of words: un testo o un documento viene analizzato sulal base delle parole che lo compongono, individuando parole chiave che ne permettano un’analisi con diversi scopi.
I dati utilizzati in questo ambito hanno le applicazioni più disparate: si passa dalla customer experience, fino all’ambito assicurativo,finanziario e di marketing.
E quali dati vengono utilizzati per queste attività? I dati vengono estratti principalmente da blog, articoli, ma soprattutto commenti e recensioni su diverse tipologie di siti online, così come i questionari.
Arriviamo però al cuore di questo articolo: come sfruttare NLP e machine learning per diverse tipologie di problemi: vediamo alcuni esempi pratici delle sfide alle quali un data scientist dovrà rispondere.
Un problema comune è il raggruppamento di documenti simili tra loro, che è traducibile come un’attività di clustering: in questo caso, un algoritmo come k-means è sicuramente indicato.
Nel caso in cui sia necessario etichettare dei documenti in base a dei termini specifici, oppure analizzare il sentiment di un documento o ridurne la dimensione, abbiamo a che fare con problemi di classificazione.
Per questa tipologia di attività, possiamo utilizzare diversi algoritmi come Naive-Bayes, alberi di decisione, reti neurali o anche la regressione.
E se dovessimo scoprire l’argomento principale di una raccolta di documenti?
In questo caso, si tratta di topic model e un algoritmo che possiamo usare è LDA, ossia un algoritmo che usa il modello bayesiano per individuare il contesto di cun documento, molto utilizzato in ambito SEO, o anche dei dizionari ad hoc per la lingua utilizzata.
Non meno importante, nell’ambito dell’analisi dei link per il web mining, abbiamo un problema molto simile alla social network analysis, perché permette di analizzare e individuare relazioni tra diversi oggetti in un gruppo sociale.
In questo caso, abbiamo moltissimi algoritmi diversi a seconda dello scopo specifico: tra i più famosi c’è sicuramente PageRank, che assegna un peso ad ogni elemento presento in un insieme di documenti collegati.
Da non sottovalutare gli alberi di decisione, che rappresenta uno strumento perfetto trattandosi di un processo gerarchico che ben rappresenta la rete che si crea grazie a link connessi tra loro.
Altre opzioni sono sicuramente Naive-Bayes, macchine a vettori di supporto e reti neurali, tutti algoritmi che si prestano bene a dataset lineari e non così come lo sono i dati estratti con il web mining.
Se questo articolo ti è piaciuto, non dimenticare di condividerlo!
Risorse utili
- Analisi del linguaggio naturale con Python - Apogeo Editore



