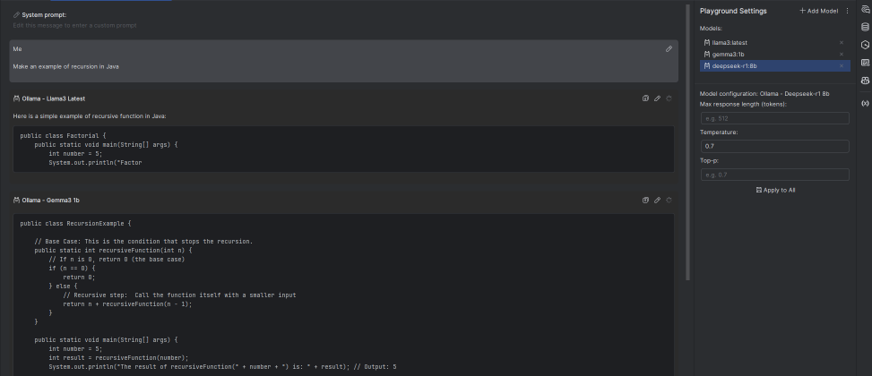
Memory scheduling in Ollama

Guardare dietro le quinte di come funzionano i modelli di linguaggio di grandi dimensioni (LLM) è fondamentale per comprendere le loro prestazioni e limitazioni, e uno degli aspetti più critici è la gestione della memoria, che influisce direttamente sulla velocità di risposta e sulla capacità del modello di mantenere il contesto durante una conversazione. In questo articolo, esploreremo come Ollama, una piattaforma per l’esecuzione di LLM, gestisce la memoria e quali strategie utilizza per ottimizzare le prestazioni.
Scheduling della memoria in Ollama
Quando parliamo di modelli di linguaggio di grandi dimensioni (LLM), la gestione efficiente della memoria è cruciale per garantire prestazioni ottimali e ridurre i tempi di latenza. Ollama, una piattaforma emergente per l’esecuzione di LLM, implementa diverse strategie per ottimizzare l’uso della memoria durante il caricamento e l’esecuzione dei modelli.
Per prima cosa, è importante parlare di come l’engine di Ollama carica i modelli in memoria. Negli ultimi rilasci, è stato introdotto un sistema che serve a misurare l’esatta quantità di memoria richiesta per ogni modello. Questo consente a Ollama di allocare dinamicamente la memoria necessaria, evitando sprechi e migliorando l’efficienza complessiva.
Come funziona la gestione della memoria in Ollama
Come spiegato anche in questo articolo, Ollama carica i modelli in memoria al bisogno. Quando il modello viene caricato, è in grado di processare le richieste in modo efficiente, ma se la memoria disponibile è insufficiente, Ollama può adottare diverse strategie per gestire la situazione, come gestire le richieste tramite una coda o rilasciare modelli meno utilizzati dalla memoria.
Questo significa che, per fare una similitudine, come avviene per i container, ogni modello viene trattato come un’istanza separata nella memoria, e Ollama si occupa di allocare e deallocare risorse in base alle esigenze del carico di lavoro. Per capire meglio, provate ad eseguire il comando:
ollama run gemma:latest
e fate qualche domanda. Poi, aprite un altro terminale e caricate un altro modello:
ollama run llama2:13b
Noterete che, se la memoria non è sufficiente per caricare entrambi i modelli contemporaneamente, Ollama gestirà la situazione in modo da garantire che almeno uno dei modelli sia sempre disponibile per l’elaborazione delle richieste. In pratica, con il comando
ollama ps
potete vedere quali modelli sono attualmente caricati in memoria e come Ollama gestisce le risorse, e ne noterete solo uno.
Ottimizzazione della memoria
Quando si parla di ottimizzazione della memoria, nel contesto dei LLM, ci sono due aspetti a cui prestare attenzione, ossia la KV Cache e la Flash Memory.
Per quanto riguarda la KV Cache, Ollama implementa una gestione intelligente che consente di mantenere in memoria solo le parti più rilevanti del contesto della conversazione, riducendo così l’uso complessivo della memoria senza compromettere la qualità delle risposte generate dal modello.
Parliamo del meccanismo di self-attention, che consente al modello di “ricordare” le informazioni più importanti durante una conversazione e fa parte dell’architettura Transformer. Ollama usa la self-attention per ottimizzare l’uso della memoria, mantenendo in memoria solo le informazioni più rilevanti per la conversazione in corso. In questo modo, implementa un meccanismo di cache, che permette di ridurre l’uso delle risorse computazionali e migliorare le prestazioni complessive del modello.
Poi, esiste la Flash Memory, che consiste in un algoritmo di gestione efficiente della memoria per migliorare la velocità di inferenza attraverso l’uso di meccanismi di tiling e streaming. In pratica, Ollama suddivide i dati in blocchi più piccoli (tiling) e li elabora in modo incrementale (streaming), riducendo così il carico sulla memoria e migliorando la velocità di risposta del modello e processando dinamicamente i chunk di token. Inoltre, va a minimizzare l’accesso alla memoria durante l’inferenza, migliorando ulteriormente le prestazioni complessive del modello, e utilizzando tecniche come la computazione Softmax per ridurre il carico computazionale.
Da questo punto di vista, è evidente che la gestione della memoria influenza il tipo di risultato che otteniamo dai modelli. Infatti, se la memoria è insufficiente, il modello potrebbe non essere in grado di mantenere il contesto della conversazione, portando a risposte meno coerenti o pertinenti.
Per questo, è possibile configurare quello che si chiama tipo di quantizzazione del modello, che influisce direttamente sull’uso della memoria.
In cosa consiste la quantizzazione? Semplice: è un processo che riduce la precisione numerica dei pesi del modello e delle attivazioni, permettendo di risparmiare memoria a discapito di una (leggera, dipende) perdita di qualità. In altre parole, si tratta di compressione dei dati che consente di ridurre la quantità di memoria necessaria per eseguire il modello. Per approfondire questo argomento, pubblicherò un articolo dedicato a breve.
🔗 Leggi anche:
Articoli Correlati