Quantizzazione in un modello linguistico con Ollama

In un precedente articolo, abbiamo parlato di come Ollama gestisce la memoria durante il caricamento e l’esecuzione dei modelli di linguaggio di grandi dimensioni (LLM). Un aspetto cruciale di questa gestione è la quantizzazione del modello, una tecnica che consente di ridurre l’uso della memoria a discapito di una leggera perdita di precisione.
Cosa vuol dire quantizzazione?
Si tratta di un processo che riduce la precisione numerica dei pesi del modello e delle attivazioni, permettendo di risparmiare memoria a discapito di una (leggera, dipende) perdita di qualità. In altre parole, si tratta di compressione dei dati che consente di ridurre la quantità di memoria necessaria per eseguire il modello.
Ad esempio, utilizzando una quantizzazione a 8 bit invece di 16 bit, si riduce significativamente l’uso della memoria, permettendo di caricare modelli più grandi o di eseguire più modelli contemporaneamente. Si può arrivare fino a una quantizzazione a 4-bit, che riduce notevolmente l’uso della memoria, ma portando anche del degrado nella qualità delle risposte, e per questo viene difficilmente utilizzata in scenari di produzione. Tuttavia, alcuni modelli, come quelli che presentano il prefisso q4 wizardlm, usano questa tecnica per bilanciare l’uso della memoria e le prestazioni.
Come funziona?
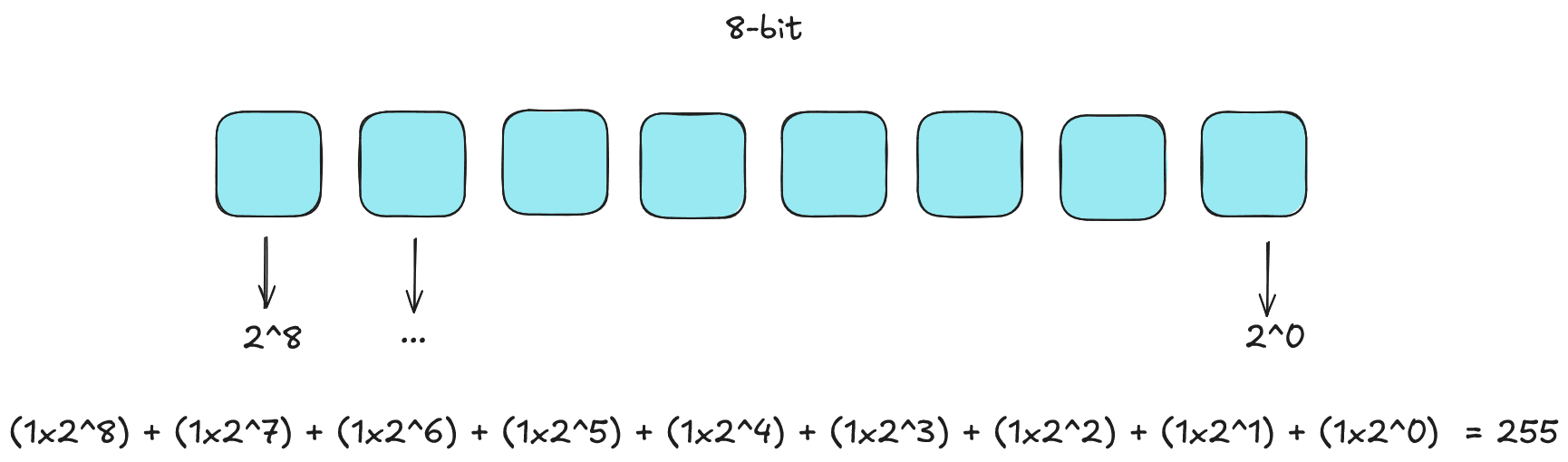
Torniamo alle basi dell’informatica e ripartiamo dal sistema binario, che utilizza solo due simboli, 0 e 1, per rappresentare i dati. Ogni cifra binaria (bit) può assumere uno di questi due valori. La quantità di informazioni che possiamo rappresentare con un certo numero di bit dipende dalla potenza di 2. Ad esempio, con 1 bit possiamo rappresentare 2 valori (0 e 1), con 2 bit possiamo rappresentare 4 valori (00, 01, 10, 11), con 3 bit possiamo rappresentare 8 valori (000, 001, 010, 011, 100, 101, 110, 111) e così via. Nell’esempio seguente, mostriamo come convertire un numero binario in decimale facendo la somma delle potenze di 2 corrispondenti ai bit attivi (e quindi pari a 1) e qual è l’intervallo di numeri rappresentabili con un certo numero di bit.
Immaginiamo quindi di voler mappare un insieme di numeri in virgola mobile che va da 0.0 a 1000.0 utilizzando un range di valori rappresentabili con 8 bit. Con 8 bit, possiamo rappresentare 256 valori distinti (da 0 a 255). Per mappare il nostro intervallo di numeri in virgola mobile (0.0 a 1000.0) ai valori rappresentabili con 8 bit, dobbiamo calcolare il fattore di scala, così che il numero 0.0 nella notazione in virgola mobile corrisponda al valore 0 in notazione a 8 bit, e il numero 1000.0 corrisponda al valore 255 in notazione a 8 bit.
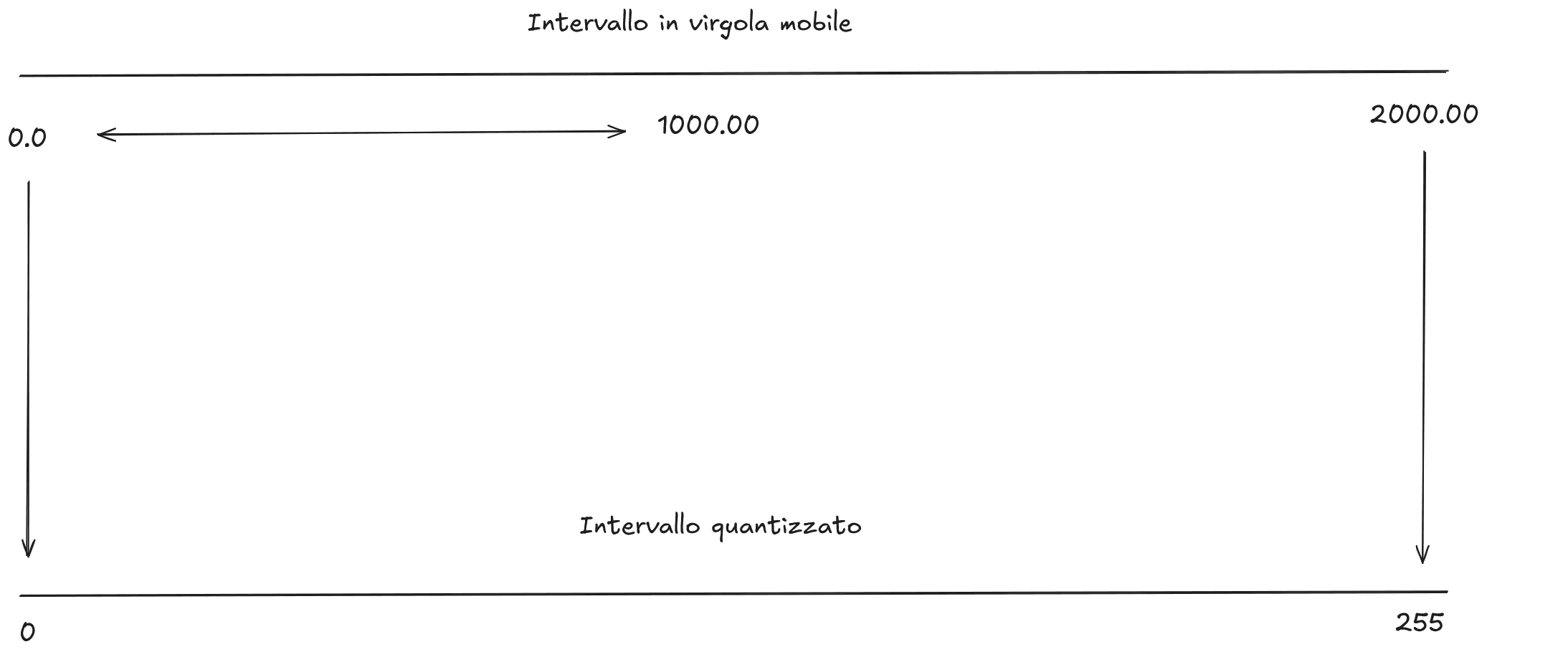
Questo tipo di mappatura si chiama quantizzazione simmetrica e può essere calcolata con la seguente formula:
scale = (max_value - min_value) / (max_quantized_value - min_quantized_value)
Dove:
max_valueè il valore massimo dell’intervallo in virgola mobile (1000.0 in questo caso).min_valueè il valore minimo dell’intervallo in virgola mobile (0.0 in questo caso).max_quantized_valueè il valore massimo rappresentabile con 8 bit (255).min_quantized_valueè il valore minimo rappresentabile con 8 bit (0).
Quindi, il fattore di scala sarà:
scale = (1000.0 - 0.0) / (255 - 0) = 1000.0 / 255 ≈ 3.9216
Questo vuol dire che, per ogni incremento di 1 nel valore quantizzato a 8 bit, il corrispondente incremento nel valore in virgola mobile sarà di circa 3.9216. Quindi, per convertire un valore in virgola mobile come 200 al suo equivalente quantizzato a 8 bit, possiamo usare la seguente formula:
quantized_value = round(float_value / scale) = round(200 / 3.9216) ≈ round(51.0) = 51
Questo è il caso più semplice di quantizzazione: diverso è che l’intervallo di valori in virgola mobile non sia simmetrico o che includa numeri negativi, anche se il concetto rimane lo stesso.
Perché è importante?
Abbiamo già detto che la quantizzazione è importante perché consente di ridurre l’uso della memoria, permettendo di caricare modelli più grandi o di eseguire più modelli contemporaneamente. Questo è particolarmente utile in scenari di produzione, dove le risorse hardware possono essere limitate. Inoltre, la quantizzazione può anche migliorare le prestazioni del modello, riducendo i tempi di inferenza, poiché i calcoli con numeri a bassa precisione sono generalmente più veloci rispetto a quelli con numeri ad alta precisione. Tutto questo perché permette di rappresentare dei valori numerici (come i pesi) con meno bit, riducendo così la quantità di memoria necessaria per memorizzarli e i calcoli necessari per elaborarli.
I modelli “tradizionali” di LLM usano numeri in virgola mobile a 32 bit (FP32) o a 16 bit (FP16) per rappresentare i pesi e le attivazioni. Tuttavia, con la quantizzazione, possiamo ridurre ulteriormente la precisione numerica, utilizzando ad esempio numeri interi a 8 bit o addirittura a 4 bit.
Come si configura in Ollama?
Questo tipo di configurazione può essere effettuata durante il caricamento del modello, specificando il tipo di quantizzazione desiderata. Ad esempio, immaginiamo di voler scaricare un modello da HuggingFace con hfdownloader e di voler specificare una quantizzazione a 8 bit. Il comando sarà il seguente:
hfdownloader -m NousResearch/Hermes-2-Theta-Llama-3-8B
In alternativa, possiamo specificare uno dei modelli a disposizione all’interno del Modelfile, come in questo caso, che specifica il template utilizzare:
FROM llama3.1:8b-instruct-fp16
TEMPLATE """{{ if .System }}<|im_start|>system
{{ .System }}<|im_end|>{{ end }}
<|im_start|>user
{{ .Prompt }}<|im_end|>
<|im_start|>assistant
"""
PARAMETER stop <|start_header_id|>
PARAMETER stop <|end_header_id|>
PARAMETER stop <|eot_id|>
Poi, per crearne una versione quantizzata a 8 bit, possiamo utilizzare il comando:
ollama create llama3-q8bit -f .\Modelfile --quantize Q8_0
A quel punto, a processo ultimato, potremo eseguire il modello con:
ollama run --verbose llama3-q8bit
Le opzioni supportate per la quantizzazione sono F32, F16, Q4_K_S, Q4_K_M, Q8_0, dove questi significano: F32 (floating point a 32 bit), F16 (floating point a 16 bit), Q4_K_S (quantizzazione a 4 bit con kernel small), Q4_K_M (quantizzazione a 4 bit con kernel medium) e Q8_0 (quantizzazione a 8 bit).
Quando parliamo di “quantizzazione con kernel” small o medium, ci riferiamo a diverse tecniche di quantizzazione che bilanciano quelli che sono i valori di perplexity (ossia quella metrica che permette di valutare il degrado dell’accuratezza) e la dimensione del modello.
In generale, la quantizzazione con kernel small tende a produrre modelli più piccoli ma con una leggera perdita di qualità rispetto alla quantizzazione con kernel medium, che invece cerca di mantenere una migliore qualità a discapito di una dimensione leggermente maggiore.
Conclusioni
In questo articolo, abbiamo esplorato il concetto di quantizzazione nei modelli di linguaggio di grandi dimensioni (LLM) e come questa tecnica possa essere utilizzata per ottimizzare l’uso della memoria e migliorare le prestazioni dei modelli. Abbiamo visto come la quantizzazione riduca la precisione numerica dei pesi del modello, permettendo di risparmiare memoria a discapito di una leggera perdita di qualità. Teniamo conto che la quantizzazione è una tecnica potente, ma deve essere utilizzata con attenzione, poiché una quantizzazione troppo aggressiva può portare a una perdita significativa di qualità nelle risposte generate dal modello. Pertanto, è importante bilanciare le esigenze di memoria e prestazioni con la qualità desiderata delle risposte del modello, soprattutto a seconda del contesto applicativo in cui viene utilizzato.



