Ollama su OpenShift: come eseguire modelli di linguaggio localmente in un ambiente sicuro

Negli ultimi anni, l’adozione di modelli di linguaggio di grandi dimensioni (LLM) è cresciuta esponenzialmente, rivoluzionando il modo in cui interagiamo con la tecnologia. Tuttavia, l’uso di questi modelli spesso comporta preoccupazioni legate alla privacy, alla sicurezza e alla dipendenza da servizi cloud esterni. Ollama, una piattaforma che consente di eseguire LLM localmente, offre una soluzione interessante per affrontare queste sfide. In questo articolo, esploreremo come implementare Ollama su OpenShift, una piattaforma di containerizzazione basata su Kubernetes, per sfruttare i vantaggi dei LLM in un ambiente sicuro e controllato, insieme a OpenWeb UI, per una gestione semplificata dei modelli.
Ollama su OpenShift: perché?
Di base, Ollama permette agli sviluppatori di eseguire modelli di linguaggio avanzati direttamente sui propri dispositivi, eliminando la necessità di inviare dati sensibili a server esterni. Questo è particolarmente importante in settori come la sanità, la finanza e il governo, dove la protezione dei dati è cruciale.
Nel contesto in cui Ollama assume un ruolo centrale all’interno di un ecosistema più grande, fatto di altri componenti che interagiscono tra loro, l’adozione di OpenShift come piattaforma di orchestrazione dei container offre numerosi vantaggi:
- Sicurezza: OpenShift fornisce funzionalità di sicurezza avanzate, come la gestione delle identità e degli accessi (IAM), che aiutano a proteggere i dati sensibili elaborati dai modelli Ollama.
- Scalabilità: OpenShift consente di scalare facilmente le risorse in base alla domanda, garantendo che le applicazioni basate su Ollama possano gestire carichi variabili senza interruzioni.
- Gestione semplificata: OpenShift offre strumenti integrati per la gestione dei container, facilitando il deployment, l’aggiornamento e il monitoraggio delle applicazioni basate su Ollama.
Fortunatamente, l’integrazione è sufficientemente semplice grazie alla natura containerizzata di Ollama.
Passaggi per implementare Ollama su OpenShift
1. Preparazione dell’ambiente OpenShift
Prima di iniziare, assicurati di avere accesso a un cluster OpenShift. Puoi utilizzare OpenShift in sandbox, on cloud oppure OpenShift tramite Podman Desktop (se vuoi sapere come, trovi le istruzioni in questo articolo). Inoltre, assicurati di avere l’interfaccia a riga di comando oc installata e configurata per interagire con il tuo cluster.
2. Creazione di un progetto OpenShift (opzionale)
Crea un nuovo progetto in OpenShift per isolare le risorse relative a Ollama:
oc new-project ollama-project
Questo passaggio torna utile nel momento in cui le risorse legate a Ollama debbano essere gestite separatamente da altre applicazioni e vogliamo centralizzarle in un namespace dedicato. Non è un passaggio obbligatorio e puoi scegliere di utilizzare un progetto esistente.
3. Configurazione dello storage
Ollama richiede uno storage persistente per salvare i modelli e i dati. Configura un Persistent Volume (PV) e un Persistent Volume Claim (PVC) in OpenShift per poter gestire lo storage necessario per Ollama e OpenWeb UI. Ecco un esempio di configurazione YAML per i PVC:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: ollama-data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 30Gi
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: webui-data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 30Gi
Chiaramente, la dimensione dello storage può variare in base ai modelli che si intende utilizzare e alla quantità di dati da gestire; teniamo quindi presente che i valori indicati sono puramente esemplificativi. Inoltre, il provisioning dello storage dipende dalla configurazione del cluster OpenShift in uso: in questo caso, si suppone che una volta creata la PVC, il relativo PV venga creato automaticamente.
4. Creazione del Deployment per Ollama e OpenWeb UI
Per installare Ollama e OpenWeb UI su OpenShift, è necessario creare un Deployment che definisca i container da eseguire. Ecco un esempio di configurazione YAML per il Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: ollama
spec:
replicas: 1
selector:
matchLabels:
app: ollama
template:
metadata:
labels:
app: ollama
spec:
containers:
- name: ollama
image: ollama/ollama:0.15.5-rc1-rocm
ports:
- containerPort: 11434
volumeMounts:
- name: ollama-data
mountPath: /.ollama
tty: true
volumes:
- name: ollama-data
persistentVolumeClaim:
claimName: ollama-data
restartPolicy: Always
---
apiVersion: v1
kind: Service
metadata:
name: ollama
spec:
ports:
- protocol: TCP
port: 11434
targetPort: 11434
selector:
app: ollama
In questo caso, abbiamo definito un Deployment per Ollama che utilizza l’immagine Docker ufficiale di Ollama. Abbiamo anche montato il volume persistente per salvare i dati di Ollama creato in precedenza, definito la porta da cui Ollama ascolterà le richieste e creato un Service per esporre Ollama all’interno del cluster OpenShift sulla medesima porta.
Nota: il tag dell’immagine utilizzato è quello più recente a disposizione al momento della stesura di questo articolo; ti consiglio di verificare la disponibilità di versioni più aggiornate sul repository ufficiale di Ollama su Docker Hub.
Per la parte legata a OpenWeb UI, possiamo creare un altro Deployment simile:
apiVersion: apps/v1
kind: Deployment
metadata:
name: open-webui
spec:
replicas: 1
selector:
matchLabels:
app: open-webui
template:
metadata:
labels:
app: open-webui
spec:
containers:
- name: open-webui
image: ghcr.io/open-webui/open-webui:main
ports:
- containerPort: 8080
env:
- name: OLLAMA_BASE_URL
value: "http://ollama:11434"
- name: WEBUI_SECRET_KEY
value: "your-secret-key"
volumeMounts:
- name: webui-data
mountPath: /app/backend/data
volumes:
- name: webui-data
persistentVolumeClaim:
claimName: webui-data
restartPolicy: Always
---
apiVersion: v1
kind: Service
metadata:
name: open-webui
spec:
ports:
- protocol: TCP
port: 8080
targetPort: 8080
selector:
app: open-webui
---
kind: Route
apiVersion: route.openshift.io/v1
metadata:
name: open-webui
spec:
to:
kind: Service
name: open-webui
weight: 100
port:
targetPort: 8080
tls:
termination: edge
insecureEdgeTerminationPolicy: Redirect
wildcardPolicy: None
Anche in questo caso, abbiamo definito il Deployment per OpenWeb UI, utilizzando l’immagine ufficiale disponibile su GitHub Container Registry. Abbiamo configurato le variabili d’ambiente necessarie per collegare OpenWeb UI a Ollama e montato il volume persistente per salvare i dati di OpenWeb UI. Inoltre, il Service ci permette di esporre OpenWeb UI all’interno del cluster sulla porta 8080, mentre la Route consente di accedere a OpenWeb UI dall’esterno del cluster OpenShift.
Per creare la route, è possibile anche utilizzare il seguente comando che genera automaticamente la configurazione della route per il servizio OpenWeb UI in modalità edge, ossia con terminazione SSL:
oc create route edge --service open-webui
5. Pull dei modelli Ollama
Ora, prima di accedere alla pagina di OpenWeb UI o di iniziare a utilizzare Ollama, è necessario scaricare i modelli desiderati. Puoi farlo eseguendo un pod temporaneo che monta lo stesso volume persistente utilizzato da Ollama. Ecco un esempio di comando per eseguire un pod temporaneo:
oc exec -it <ollama-pod-name> -- ollama pull <model-name>
Con questo comando, andiamo a eseguire il comando ollama pull all’interno del pod di Ollama, scaricando il modello specificato e salvandolo nel volume persistente montato. Sostituisci <ollama-pod-name> con il nome effettivo del pod di Ollama, che puoi ottenere eseguendo oc get pods, e <model-name> con il nome del modello che desideri scaricare.
Ad esempio, per scaricare il modello Llama 2 7B:
oc exec -it <ollama-pod-name> -- ollama pull llama2:7b
Ci siamo: possiamo aprire il browser e aprire la pagina principale di OpenWebUI utilizzando l’URL fornito dalla route creata in precedenza. Da qui, possiamo iniziare a interagire con i modelli Ollama in modo semplice e intuitivo. Nella seguente schermata, vediamo ad esempio la pagina che ci permette di inserire il prompt per interagire con il modello llama3.1:8b-instruct-q4_K_M. Se non avessi fatto i compiti a casa, parliamo di un modello LLaMA 3.1 da 8 miliardi di parametri, ottimizzato per rispondere a istruzioni in linguaggio naturale, con quantizzazione Q4_K_M per un’efficienza migliorata. Della quantizzazione ne abbiamo parlato di recente in questo articolo.
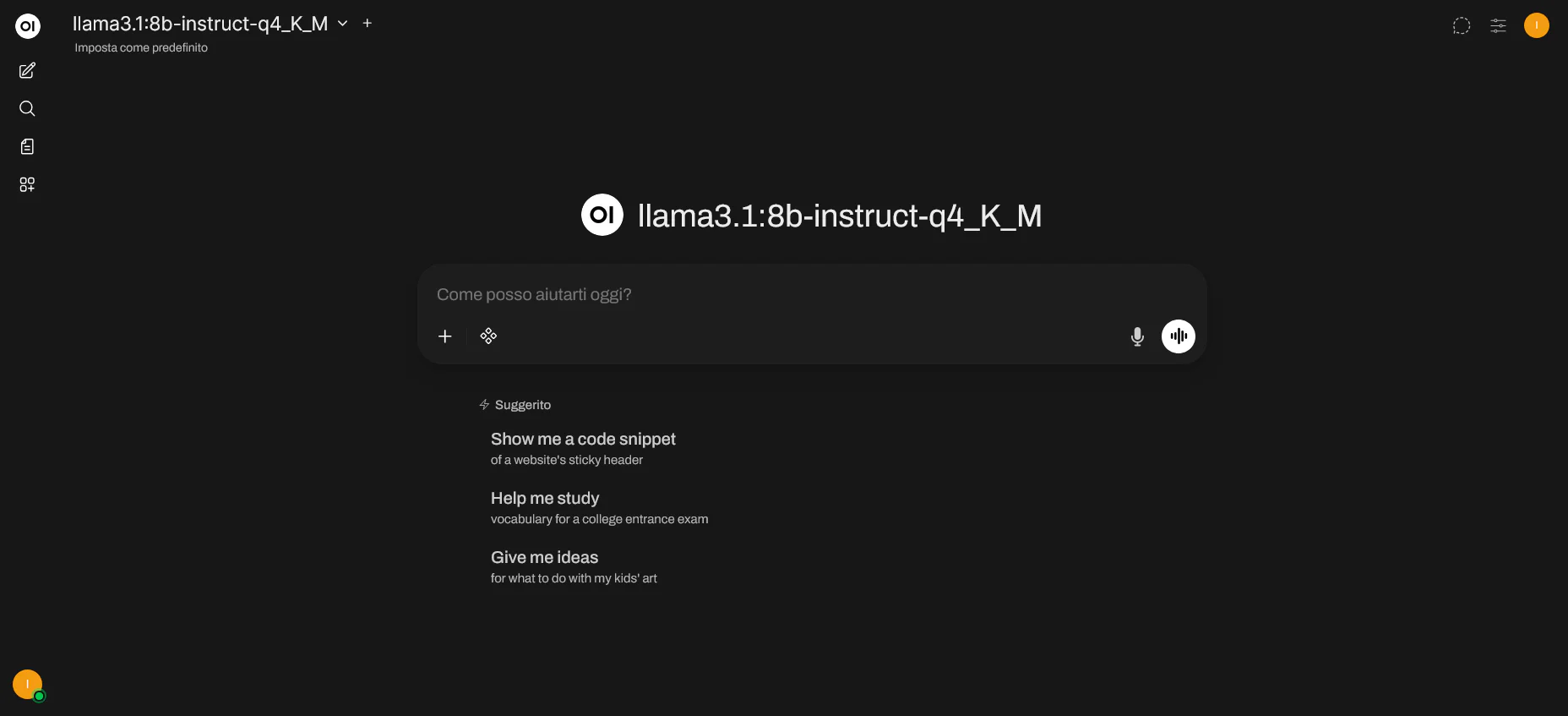
Pagina principale di OpenWebUI
Conclusioni
A questo punto, le possibilità sono infinite: possiamo esplorare i vari modelli disponibili su Ollama, testarli e integrarli nelle nostre applicazioni, ma anche lavorare con l’Arena model su OpenWeb UI per confrontare le prestazioni di diversi modelli in modo semplice e veloce, utilizzando lo stesso prompt di input e valutando le risposte generate.
E tu, come stai utilizzando Ollama nei tuoi progetti? Hai già sperimentato l’implementazione su OpenShift o altre piattaforme? Condividi la tua esperienza nei commenti!



