Alcune riflessioni su DeepSeek

Di DeepSeek se ne parla tanto (troppo?), da diverse settimane ormai. Ci sono alcune verità “scomode” di cui parla molto poco, che riguarda com’è nata quest’azienda, le sue licenze, come questo modello è stato addestrato e la sua sostenibilità.
TOC
- Licenze e Open Source
- Chip utilizzati e sostenibilità
- Parametri e benchmark
- Costo
- Dov’è l’innovazione?
- Conclusioni
DeepSeek è una startup cinese emergente nel campo dell’intelligenza artificiale, fondata nel maggio 2023 da Liang Wenfeng a Hangzhou, una città nota per la sua concentrazione di aziende tecnologiche. Liang, ex hedge fund manager, ha creato DeepSeek con un capitale iniziale di 1,4 milioni di dollari e ha riunito un team di giovani talenti provenienti dalle migliori università cinesi per sviluppare modelli di intelligenza artificiale open-source.
Insomma, altro che la solita favola del team di 4 dev che lavora in un garage…
Se il nome del suo fondatore non vi dicesse niente, allora proviamo a dare qualche informazione in più: Wenfeng ha creato High-Flyer, inizialmente, conosciuto come Fire-Flyer, che rappresentava il ramo dedicato al deep learning dell’hedge fund High-Flyer, fondato nel 2015. DeepSeek è stata fondata come una filiale di High-Flyer, permettendo alla startup di sviluppare modelli di intelligenza artificiale senza la pressione di investitori esterni, e avendo già un capitale iniziale con cui iniziare a lavorare.
Sicuramente DeepSeek, in quanto estensione di High-Flyer, riflette la visione innovativa di Wenfeng e il suo impegno nella ricerca avanzata in intelligenza artificiale.
Licenze e Open Source
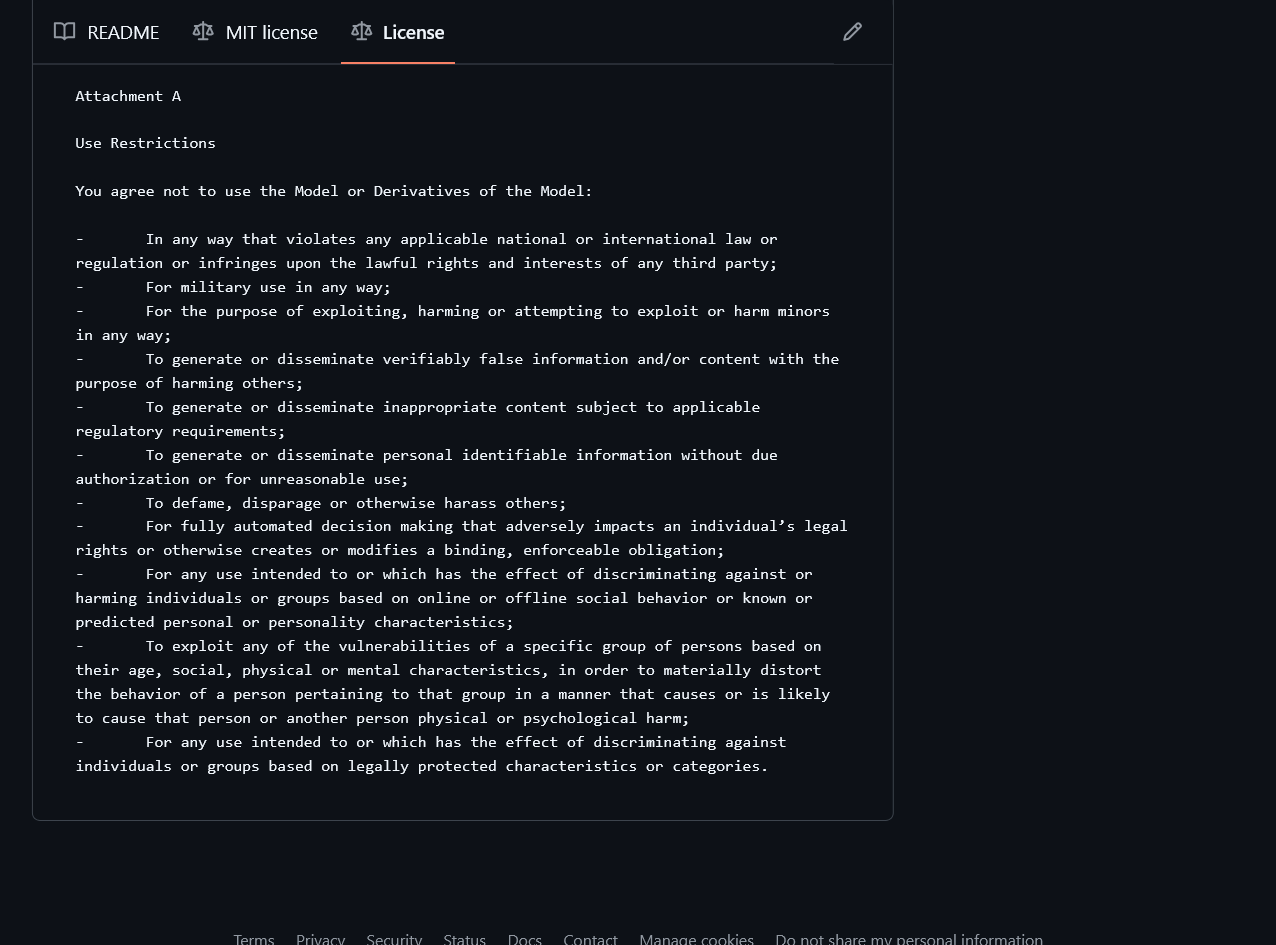
Il modello DeepSeek-R1 è rilasciato con una licenza MIT che è sì open-source, consentendo a chi sviluppa di utilizzarlo liberamente, anche per scopi commerciali, con le sole condizioni rispetto al copyright e al testo della licenza MIT che devono essere inclusi in ogni copia o parte sostanziale del software. Questa caratteristica distingue DeepSeek dai suoi concorrenti più noti, come OpenAI, e aggiunge sicuramente un bel competitor nel mercato attuale dei LLM.
L’aspetto interessante sta all’interno del file di licenza sul modello: esistono diversi punti che parlano, per esempio, del divieto esplicito del modello per usi illeciti, come l’uso del modello in violazione delle leggi applicabili o per scopi militari, il divieto di generare o diffondere informazioni false o di utilizzare il modello per decisioni automatizzate che influenzano i diritti legali degli individui. Si dettaglia anche il divieto utilizzare il modello in modi che discriminano o danneggiano individui o gruppi basati su caratteristiche protette.
Inutile dire che si tratta di considerazioni assolutamente lecite, ma non scontate, soprattutto se guardiamo al background del prodotto, e soprattutto se consideriamo che molti di questi aspetti sono dettagliati nell’AI Act, che però riguarda solo l’Europa, e a cui non aderiscono altri Stati.
Chip utilizzati e sostenibilità
Per l’addestramento dei suoi modelli, DeepSeek ha utilizzato i chip Nvidia H800, che sono meno avanzati rispetto agli H100 impiegati da altre aziende leader nel settore.
Questo approccio ha permesso a DeepSeek di raggiungere prestazioni elevate con un utilizzo significativamente inferiore di risorse, rendendo il modello più sostenibile rispetto ai concorrenti. A pensarci bene, questo team ha dovuto lavorare duro per mantenere un’efficienza più alta con meno risorse e ottenere un prodotto di eguale o superiore prestazioni rispetto agli attuali disponibili: sotto questo punto di vista, è considerabile come occasione perfetta per innovare e riflettere su quanto la disponibilità di hardware a oggi non ci spinga invece a sfruttare a pieno quel che c’è.
Piccola nota: perché hanno usato questi chip e non gli H100, che sono più prestanti? Perché NVIDIA non può vendere acceleratori A100, A100X e H100 alle società di nazionalità cinese dallo scorso agosto dopo l’applicazione dei vincoli del Dipartimento del Commercio statunitense.
C’è anche da dire che, in realtà, HighFlyer possieda circa 50.000 schede H100 e, proprio pochi giorni fa, il CEO di Scale AI Alexandr Wang ha accusato DeepSeek di aver mentito rispetto all’utilizzo di chip meno prestanti e più economici.
Parametri e benchmark
Il modello DeepSeek-R1 gestisce 67 miliardi di parametri e ha dimostrato prestazioni competitive in vari benchmark, inclusi AIME 2024, test che valuta capacità di ragionamento matematico e problem-solving dei modelli di intelligenza artificiale e MMLU, progettato per valutare le capacità di comprensione e ragionamento dei modelli di linguaggio attraverso una serie di compiti diversificati. Questo test include domande su vari argomenti, come cultura generale, matematica, scienze e altre aree, ed è utilizzato per misurare la performance dei modelli in contesti reali e complessi.
Costo
Il costo del modello DeepSeek-R1 è notevolmente inferiore rispetto a quello di o1: DeepSeek ha adottato una strategia di prezzo aggressiva, rendendo i suoi servizi più accessibili e sfidando i prezzi delle grandi aziende tecnologiche. (dati aggiornati a gennaio 2025)
| Modello | Costo per 1M di token in INPUT (USD) | Costo per 1M di token in OUTPUT (USD) |
|---|---|---|
| DeepSeek-R1 | $0.14 | $2.19 |
| o1 | $15.00 | $60.00 |
| gpt-4o-mini | $0.150 | $0.600 |
Dov’è l’innovazione?
Nel paper ufficiale che presenta DeepSeek, l’azienda sottolinea diversi punti innovativi riguardanti le capacità avanzate del modello R1, in particolare la sua abilità nel ragionamento e nella gestione delle richieste complesse. Questi aspetti posizionano DeepSeek come un attore significativo nel panorama dell’IA open-source.
Non è una novità invece che questo modello usi l’apprendimento per rinforzo, che risulta essere ad oggi l’algoritmo perfetto per migliorare le prestazioni attraverso feedback e interazioni con l’ambiente, rendendolo versatile e capace di affrontare diversi compiti in modo efficace.
C’è una nota interessante nel paper, che riguarda l’utilizzo di reinforcement learning with cold start: si riferisce a una situazione in cui un modello deve iniziare a prendere decisioni o a interagire con un ambiente senza avere dati storici o esperienze precedenti su cui basarsi Questo scenario va quindi a risolvere il cosiddetto problema dell’avvio a freddo, che si riferisce a situazioni in cui, a causa della mancanza di sufficienti interazioni utente-componente, un modello non riesce a fornire risposte utili.
Si tratta di un caso piuttosto comune in contesti in cui il modello deve affrontare nuove situazioni o ambienti in cui non ha mai operato prima, rendendo difficile l’apprendimento iniziale delle strategie ottimali. In generale, il “cold start” rappresenta una sfida significativa poiché il modello deve esplorare attivamente l’ambiente per raccogliere informazioni e apprendere le dinamiche necessarie per ottimizzare le sue decisioni, il che può richiedere tempo e risorse considerevoli.
Conclusioni
Si tratta sicuramente di un progetto che ha delle ottime premesse, ampiamente discusse, e anche delle promesse da mantenere: la sostenibilità hardware su lungo termine, ora che si rende evidente la possibilità di utilizzare meno risorse per modelli più efficienti, così come la sostenibilità economica e la possibilità di diffondere il proprio prodotto a macchia d’olio, grazie all’uso di licenze che rendono il modello accessibile ad un approccio collaborativo.
Altro aspetto interessante è la sostenibilità sociale: pubblicare il codice del modello sotto licenza MIT con un paper che ne dettaglia l’approccio tecnico, la sperimentazione e i limiti aumenta la trasparenza, permettendo agli utenti di esaminare il codice e comprendere come funziona il modello.
Tutte queste attenzioni sono particolarmente importanti per affrontare questioni etiche e di sicurezza legate all’uso dell’IA da qui ai prossimi anni e di cui le aziende devono iniziare a preoccuparsi.



