Usare YOLOv11 per la diagnosi precoce del cancro della pelle

Come creare un modello in grado di rilevare dei potenziali tumori della pelle usando un algoritmo di object detection?
Abbiamo già parlato di YOLO: sta per “You Only Look Once” ed è una famiglia di algoritmi di rilevamento di oggetti in tempo reale progettati per identificare e classificare in modo efficiente degli elementi all’interno delle immagini. Introdotto da Joseph Redmon e dei suoi colleghi nel 2016, YOLO rappresenta un significativo progresso nella computer vision grazie alla sua velocità e precisione.
Come funziona YOLO
L’innovazione principale di YOLO risiede nella sua architettura, che elabora l’intera immagine in un singolo passaggio attraverso una rete neurale. Ciò si differenzia con i tradizionali metodi di object detection che in genere richiedono più passaggi per identificare le regioni di interesse e classificarle separatamente.
Invece, YOLO divide l’immagine di input in una griglia S×S e assegna contemporaneamente bounding box e probabilità di assegnare una determinata classe a ciascuna cella della griglia. Se il centro di un oggetto rientra in una cella della griglia, quella cella viene usata per definire l’oggetto.
Release
Fin dal suo inizio, YOLO si è evoluto attraverso diverse iterazioni:
- YOLOv1 (2016): il modello originale ha introdotto il concetto di rilevamento in tempo reale.
- YOLOv2/YOLO9000 (sempre 2016): velocità e accuratezza migliorate con normalizzazione batch e anchor box.
- YOLOv3 (2018): accuratezza migliorata utilizzando un’architettura più profonda nota come Darknet-53.
- YOLOv4 (2020): ulteriori miglioramenti in termini di velocità e accuratezza.
- YOLOv5 (2020): una versione leggera ottimizzata per avere migliori prestazioni.
Le versioni più recenti (2021-2024) includono YOLOv6, YOLOv7 e fino a YOLOv11, ognuno incentrato sul miglioramento di funzionalità quali efficienza e rilevamento multi-scala, ossia l’identificazione e la classificazione di oggetti che potrebbero essere presenti in dimensioni diverse a seconda della distanza, della prospettiva e della risoluzione.
Costruire un modello di skin cancer detection
Per testare le potenzialità di YOLOv11, andiamo ad utilizzare un dataset presente su Roboflow.com che contiene circa 1200 immagini, di cui 855 utilizzate per la fase di training, 230 per quella di validazione e 112 per il testing.
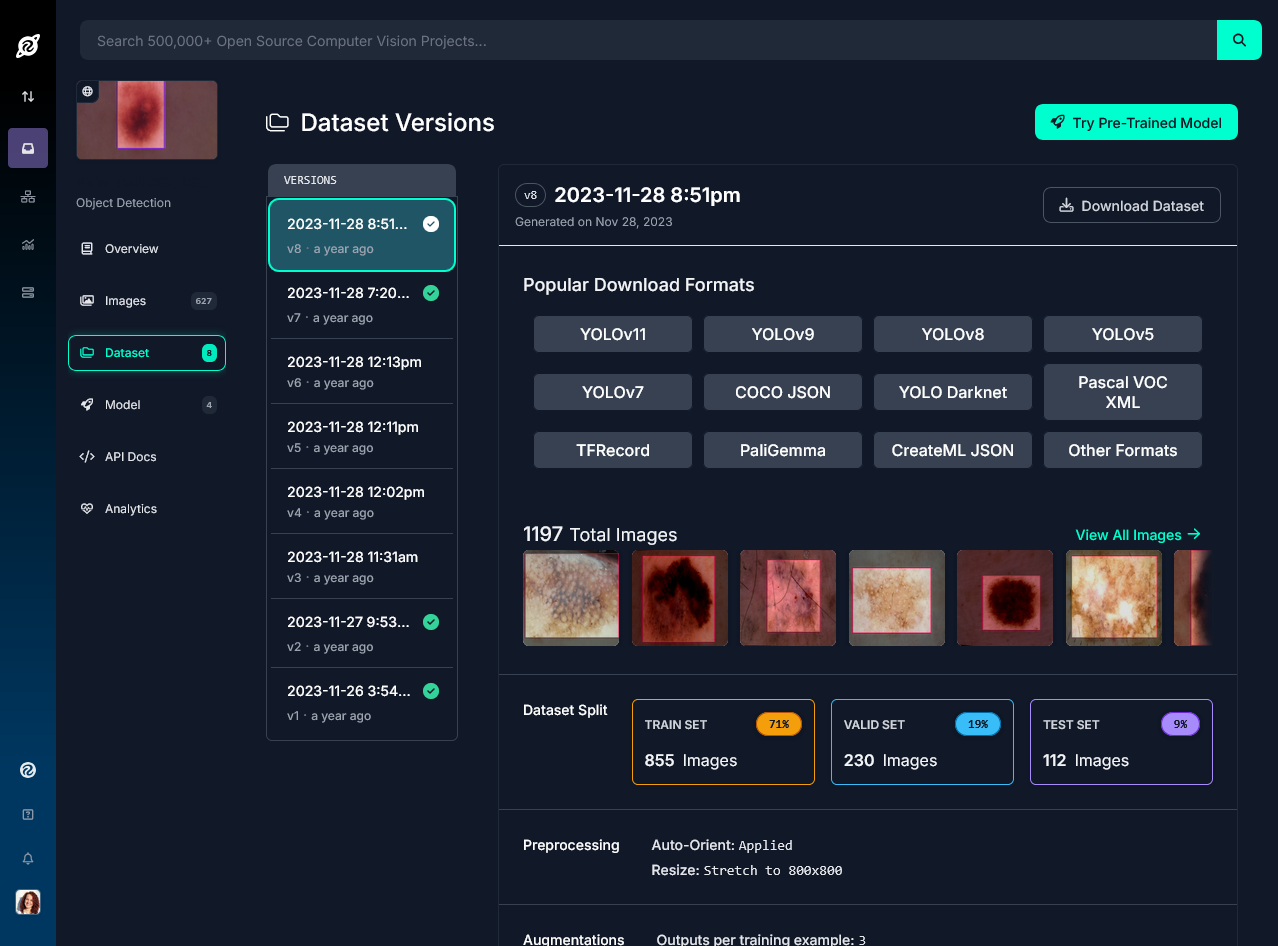
Per scaricarlo, ci sono diverse opzioni: una di queste prevede di eseguire il seguente codice Python, che permette di installare sia ultralytics come libreria per poter utilizzare YOLO, sia di eseguire il download del dataset:
# Import della libreria ultralytics
import ultralytics
# Verifica l'installazione e la configurazione di ultralytics, che controlla le dipendenze e l'hardware (GPU, se presente)
ultralytics.checks()
# Importa della libreria di Roboflow per la gestione dei dataset
from roboflow import Roboflow
# Inizializzazione Roboflow con la tua chiave API
rf = Roboflow(api_key="xyz")
# Download del dataset dal workspace desiderato
project = rf.workspace("surawiwat-school-suranaree-university-of-technology").project("skin_cancer_detection-v2")
# Specifica la versione da utilizzare
version = project.version(8)
# Scarica il dataset in formato YOLOv11 per l'addestramento
dataset = version.download("yolov11")
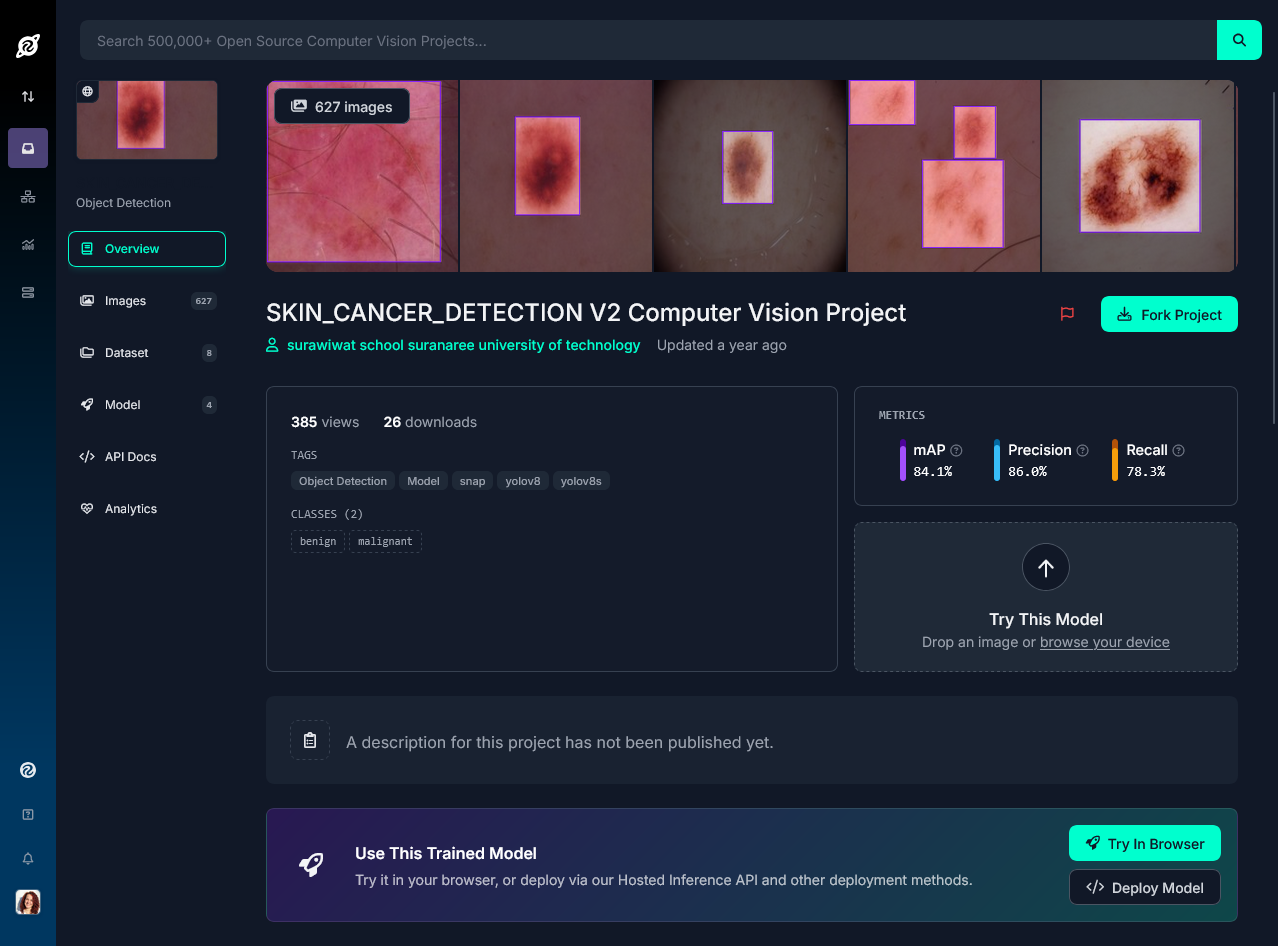
Questo dataset è solo uno dei tanti disponibili per questo tipo di attività, ma è stato scelto perché è possibile utilizzarlo anche commercialmente senza particolari restrizioni.
Alternativamente al codice Python, è possibile eseguire il download del dataset dal sito:
Una volta che avremo a disposizione il dataset, vedremo che questo ha 3 cartelle, ognuna per ogni fase dello sviluppo del modello:
Inoltre, è presente un file data.yaml che serve a descrivere come YOLO dovrà utilizzare ed interpretare il dataset: come prima cosa, definisce il nome delle due classi con cui verrà eseguita la classificazione nel corso dell’object detection. In questo caso, la classe con ID 0 rappresenta delle lesioni cutanee benigne, mentre l’ID 1 rappresenta possibili casi maligni.
Il parametro nc è fondamentale, perché rappresenta il numero delle classi da identificare.
Poi, ci sono i dettagli circa il dataset di Roboflow: la licenza, il nome, la versione e l’URL. Infine, sono presenti i riferimenti alle diverse cartelle del dataset e per che fase devono essere utilizzate.
Questa è la struttura di base che YOLO si aspetta: una cartella chiamata datasets con all’interno una struttura di cartelle di cui una per il test, una per il training e una per la fase di validazione. Se venisse eseguito il download manuale o questa non corrispondesse a questa struttura, accertatevi che segua queste direttive.
names:
- benign
- malignant
nc: 2
roboflow:
license: CC BY 4.0
project: skin_cancer_detection-v2
url: https://universe.roboflow.com/surawiwat-school-suranaree-university-of-technology/skin_cancer_detection-v2/dataset/8
version: 8
workspace: surawiwat-school-suranaree-university-of-technology
test: ../test/images
train: ../train/images
val: ../valid/images
Giusto per maggiore chiarezza, apriamo la cartella relativa al dataset e notiamo che ci sono due cartelle per ogni step, di cui una rappresentante le immagini e una le label:
Le immagini che iniziano con “b” rappresentano casi di lesioni benigne, mentre quelle che iniziano con “m”, casi di potenziali carcinomi maligni. Ad ogni immagine, corrisponde un file di testo che contiene le label che servono a YOLO per identificare l’oggetto: la prima rappresenta la classe (in questo caso, lesione benigna) e gli altri quattro numeri sono i riferimenti della bound box che rappresenta l’oggetto di interesse.
0 0.540625 0.493125 0.62125 0.494375
A questo punto, possiamo andare a eseguire questi 3 step, partendo dall’addestramento: tramite riga di comando, indichiamo a YOLO di usare il file data.yaml presente nel dataset, il modello nella versione 11 (attualmente il più recente) e poi possiamo indicare diversi parametri per raffinare il modello, come il numero di epoche, la dimensione dei batch di dati, l’algoritmo di ottimizzazione o il learning rate.
A scopo di esempio, questo è il comando che è possibile eseguire, tenendo conto che a seconda dell’hardware a disposizione, l’addestramento potrebbe durare più di qualche ora:
yolo train data=data.yaml model=yolo11n.pt epochs=100 lr0=0.01 batch=8 optimizer=adam
Quando avrà terminato, il risultato potrebbe essere simile al seguente:
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
5/5 0G 1.553 1.628 1.846 15 640: 100%|██████████| 107/107 [04:25<00:00, 2.48s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 15/15 [00:26<00:00, 1.78s/it]
all 230 248 0.584 0.569 0.569 0.277
5 epochs completed in 0.407 hours.
Optimizer stripped from runs\detect\train16\weights\last.pt, 5.5MB
Optimizer stripped from runs\detect\train16\weights\best.pt, 5.5MB
Validating runs\detect\train16\weights\best.pt...
Ultralytics 8.3.76 🚀 Python-3.12.2 torch-2.6.0+cpu CPU (Intel Core(TM) i9-8950HK 2.90GHz)
YOLO11n summary (fused): 100 layers, 2,582,542 parameters, 0 gradients, 6.3 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 15/15 [00:22<00:00, 1.52s/it]
all 230 248 0.598 0.56 0.571 0.276
benign 85 92 0.532 0.576 0.542 0.253
malignant 143 156 0.664 0.545 0.599 0.3
Speed: 1.4ms preprocess, 77.8ms inference, 0.0ms loss, 0.8ms postprocess per image
Results saved to runs\detect\train16
💡 Learn more at https://docs.ultralytics.com/modes/train
I risultati dell’addestramento vengono salvati nella cartella /runs/detect/train/. Esaminiamoli.
Ci sono una serie di cartelle per ogni epoca di training, di cui l’ultima contiene delle immagini che rappresentano metriche molto importanti per valutare il nostro modello: ci sono la matrice di confusione, la curva del F1-score, la curva di precisione e di recall, così come anche delle immagini che mostrano come il modello ha imparato dalle immagini:
È arrivato il momento di validare il modello: per farlo, eseguiamo il seguente comando:
yolo task=detect mode=val model=runs\detect\train10\weights\best.pt data=data.yaml
In questo caso, l’opzione mode=val indica che si sta eseguendo la modalità di validazione del modello. Questo è un passaggio critico per valutare le prestazioni su un set di dati di validazione, permettendo di verificare quanto bene il modello ha appreso durante l’addestramento.
Inoltre, si specifica il percorso del modello pre-addestrato che si desidera utilizzare per la validazione. In questo caso, si fa riferimento al file best.pt, che contiene i pesi ottimali del modello ottenuti dopo l’addestramento.
Il processo non sarà particolarmente lungo, e i risultati saranno salvati in runs/detect/val:
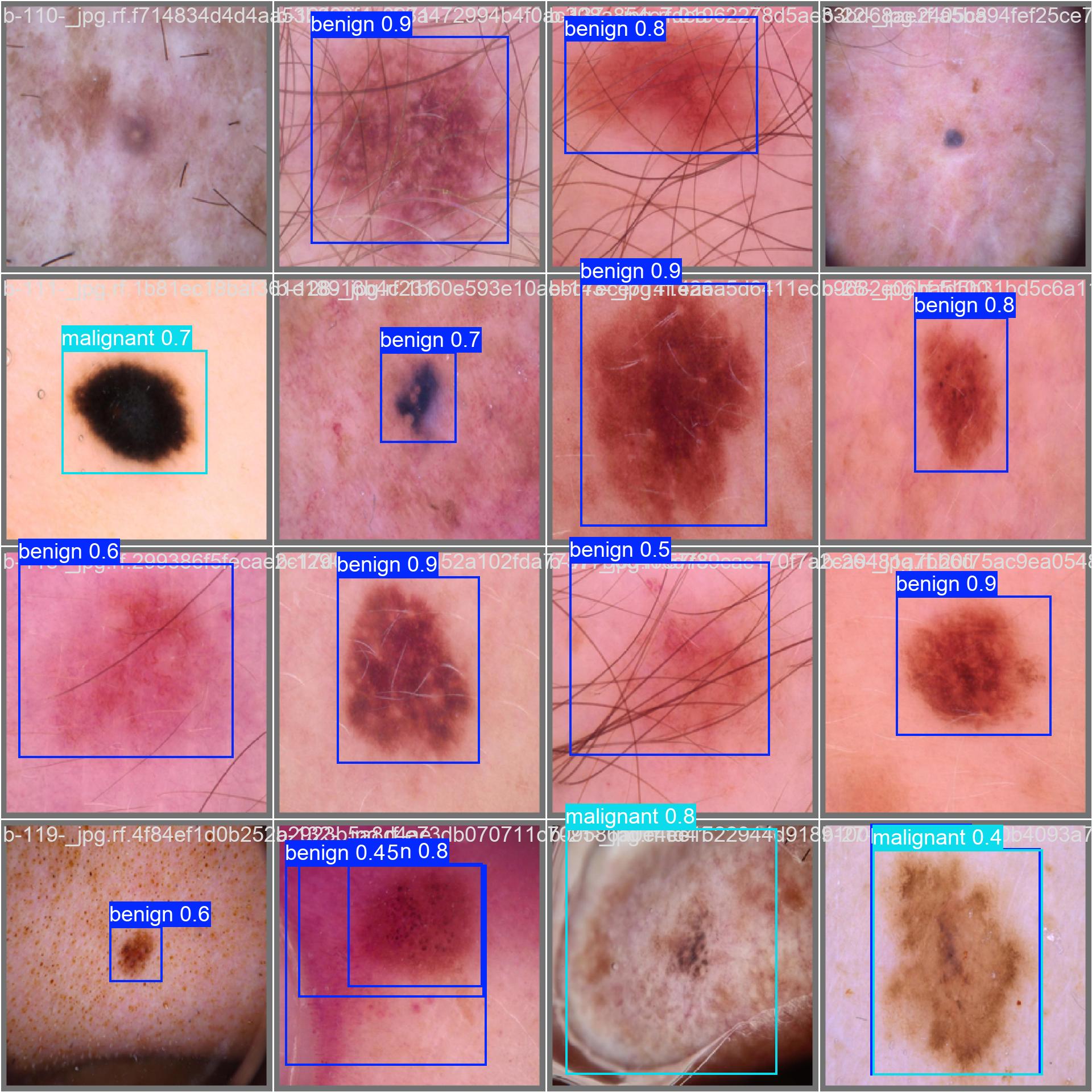
Se il risultato ci soddisfa, possiamo passare alla fase di test del modello: ci basterà eseguire il seguente comando per verificare su delle immagini mai viste come questo riconosca correttamente o meno le lesioni:
yolo task=detect mode=predict model=runs\detect\train14\weights\best.pt conf=0.25 source=test\images save=True
Questo comando andrà a utilizzare come immagini quelle presenti nella cartella di test, e andrà a salvare i risultati in una cartella chiamata predict di default, inserendovi le immagini annotate. In più, con il parametro conf=0.25 si imposta la soglia di confidenza per le predizioni. Un valore di confidenza di 0.25 significa che solo le previsioni con un punteggio del 25% o superiore saranno considerate valide.
Nota: abbassare questa soglia potrebbe portare una maggiore accuratezza, ma potrebbe anche aumentare i falsi positivi, anche se si consiglia di usare un valore più alto per modelli in produzione.
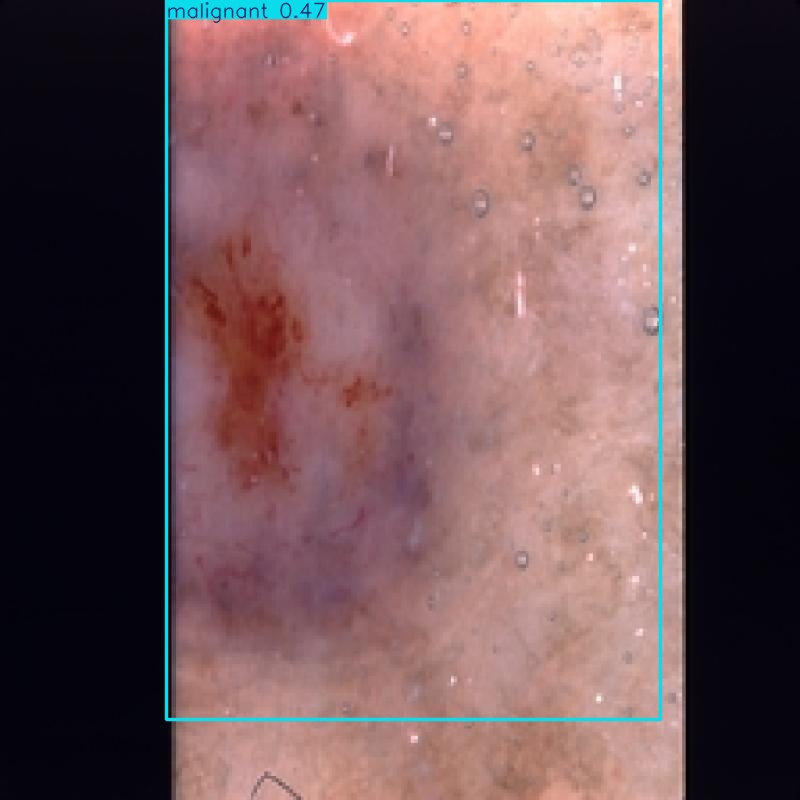
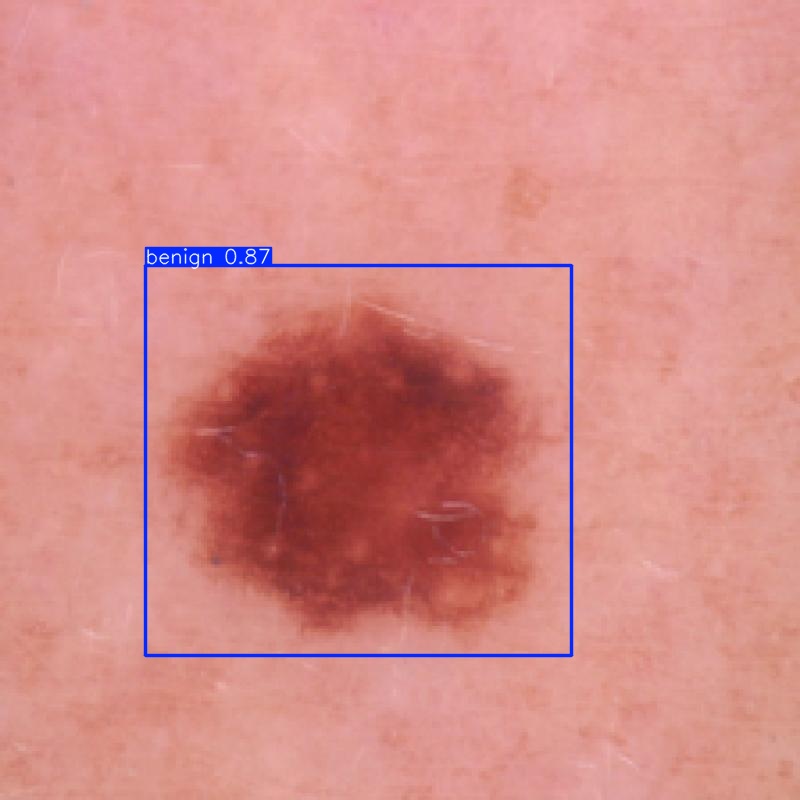
Una volta ultimata la fase di test, diamo un’occhiata al contenuto della cartella predict: aprendo alcune delle immagini, queste sono state etichettate con delle box colorate che definiscono i contorni degli oggetti cercati, e anche la classe con il relativo livello di confidenza.