Tipologie di Machine Learning

Spesso il machine learning viene accostato a della “magia” o addirittura “alchimia”: un articolo molto interessante è quello pubblicato su Different Glasses che riporto qui, per raccontare l’accostamento di queste due materie…
Ma torniamo a noi: quali sono le tipologie di machine learning che esistono? Quali sono le differenze e quale adottare a seconda del problema?
Intro
L’abbondanza di dati ha fatto sì che il machine learning sembri la soluzione ad ogni nostro problema: la realtà è che questo campo è una branca dell’intelligenza artificiale che sfrutta i dati a disposizione per effettuare delle previsioni.
E, come tali, non sono da confondersi con le predizioni: il machine learning non è astrologia, né tantomeno alchimia!
Al contrario dell’approccio manuale, il machine learning ci permette di avere un’alternativa che vada ad analizzare i dati e individuare dei modelli per costruire una generalizzazione per la rappresentazione dei dati.
Ma quali tipi di machine learning esistono e come possiamo creare una classificazione tra i vari approcci?
In questo campo, si ha una divisione tra apprendimento supervisionato, non supervisionato e apprendimento rafforzato.
Apprendimento supervisionato
Cos’è
Come facilmente intuibile dal termine, quello supervisionato prevede un controllo sui dati: in effetti, con questa tipologia di problemi andiamo a trovare un modello che, grazie a dei dati di addestramento, riesca ad avere già un set di soluzioni da cui attingere.
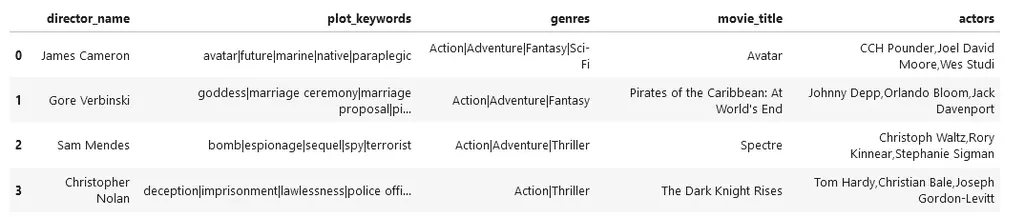 Esempio di dataset per apprendimento supervisionato: in questo caso, abbiamo dei film con relativi generi, che possono essere usati per classificarne di altri
Esempio di dataset per apprendimento supervisionato: in questo caso, abbiamo dei film con relativi generi, che possono essere usati per classificarne di altri
Algoritmi
L’esempio più semplice è quello della classificazione: in questo caso, andiamo ad associare ad ogni input una classe prendendo come riferimento le etichette fornite nel dataset.
Questo significa che, come visto nell’esempio in precedenza, se ho dei film e devo associare loro un genere, posso pensare ad un algoritmo che compia un’azione di classificazione.
Questo andrà a prendere gli esempi nel dataset di addestramento, le relative etichette, e cercare di trovare un modello che sia in grado di assegnare delle etichette a dei dati mai visti.
E con Python, quali sono gli algoritmi che abbiamo a disposizione?
Nel caso di scikit-learn, esistono diversi algoritmi che abbiamo a disposizione: regressione logistica, lasso, classificazione, SVM, e via dicendo (qui l’elenco completo).
Tensorflow anche offre una serie di algoritmi supervisionati; alcuni di questi vengono riportati di seguito:
- Linear regression: tf.estimator.LinearRegressor
- Classification:tf.estimator.LinearClassifier
- Deep learning classification: tf.estimator.DNNClassifier
- Deep learning wipe and deep: tf.estimator.DNNLinearCombinedClassifier
- Booster tree regression: tf.estimator.BoostedTreesRegressor
- Boosted tree classification: tf.estimator.BoostedTreesClassifier
Apprendimento per rinforzo
Cos’è
Con questo tipo di apprendimento, cerchiamo di far sì che l’agente (ossia il sistema) sia in grado di imparare grazie a dei premi (o talvolta delle penalizzazioni).
L’obiettivo è quello di far sì che la ricompensa arrivi ogni qualvolta l’agente riesca ad ottenere un buon risultato: possiamo pensare all’apprendimento rafforzato come un esempio di apprendimento supervisionato, dove la ricompensa misura la qualità, e non l’etichetta in sé stessa.
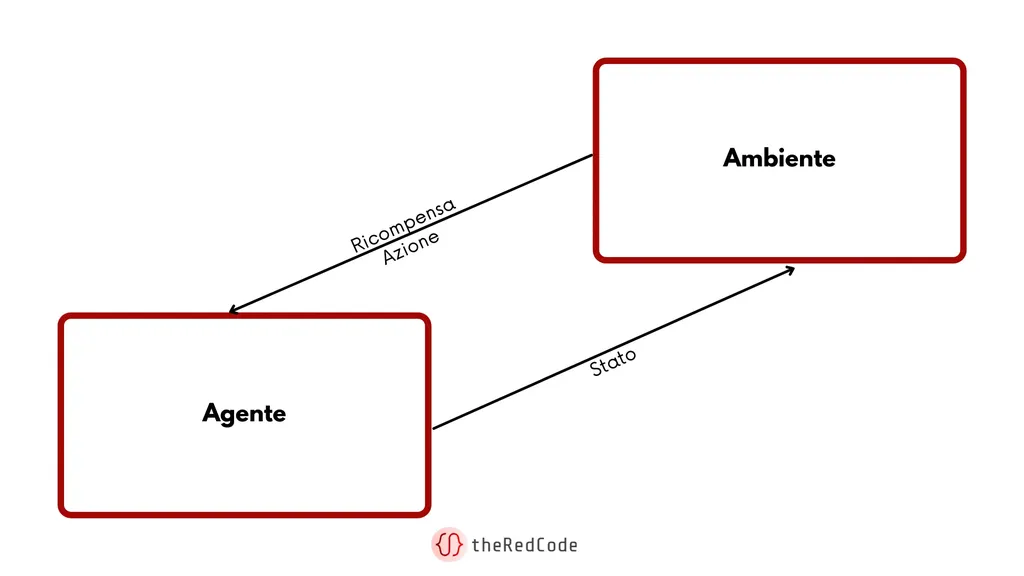 Esempio del funzionamento dell’apprendimento per rinforzo
Esempio del funzionamento dell’apprendimento per rinforzo
Algoritmi
L’esempio per eccellenza è il gioco degli scacchi: in questo caso, l’agente deve decidere quale sarà la prossima mossa a seconda dello stato della scacchiera, e la ricompensa sarà definita in base alla vittoria o alla sconfitta del sistema.
Apprendimento non supervisionato
Cos’è
Al contrario dei precedenti approcci, nell’apprendimento non supervisionato non abbiamo in anticipo una risposta giusta, né abbiamo una ricompensa per l’agente.
In questo caso, il sistema cerca di misurare delle similarità o delle differenze tra i dati forniti in input per cercare un modello che riesca a descrivere questi dati.
Algoritmi
Un esempio è il caso in cui cerchiamo di organizzare una serie di informazioni di diversi gruppi, non avendo però a priori delle categorie da assegnargli: in questo caso, si parla di clustering.
Anche in questo caso, vediamo cosa ci offrono le librerie di Python: per quanto riguarda scikit-learn, esisono moltissimi algoritmi per il clustering o la misura della covarianza (qui la documentazione).
Tensorflow e keras su questo però hanno il primato: queste librerie nascono proprio per lavorare su dati non strutturati e non etichettati, e hanno aperto le porte al mondo del deep learning.
Da non sottovalutare il mondo delle reti neurali: questo tipo di algoritmi lavora bene in entrambe le situazioni, anche se richiedono del lavoro “in più”… ma ne parleremo nella prossima puntata!
Se hai bisogno di uno schema veloce, scarica questo cheatsheet!

🔗 Leggi anche:

Articoli Correlati









