Transformers vs Seq2seq

Parlare di LLM senza introdurre il concetto di transformer è impossibile: ma cosa sono, e da dove nascono?
- Cronaca di una rete Seq2seq
- Transformer: definizione
- Come funziona un transformer
- Architettura di un transformer
Cronaca di una rete Seq2seq
Introdotto per la prima volta nel 2017 nel citatissimo paper Attention Is All You Need da Google, il transformer è stato inserito nel contesto dei modelli Sequence-to-Sequence (abbreviati in Seq2Seq), cioè dei modelli in cui data una sequenza di input, produce una sequenza di output.
I modelli Seq2Seq sono particolarmente adatti alla traduzione, in cui la sequenza di parole di una lingua viene “codificata” in una serie di parole che appartengono alla lingua in cui tradurre.
Le reti Seq2seq sono comunemente costituiti da un codificatore (aka encoder) e un decodificatore (aka decoder) e lavorano tramite quelle che si chiamano reti neurali ricorrenti, ossia dei modelli che sono stati addestrati su dati sequenziali. Suona familiare?
L’encoder prende la sequenza di input e la riporta in uno spazio vettoriale n-dimensionale. Quel vettore viene fornito al decoder, che lo trasforma a sua volta in una sequenza di output.
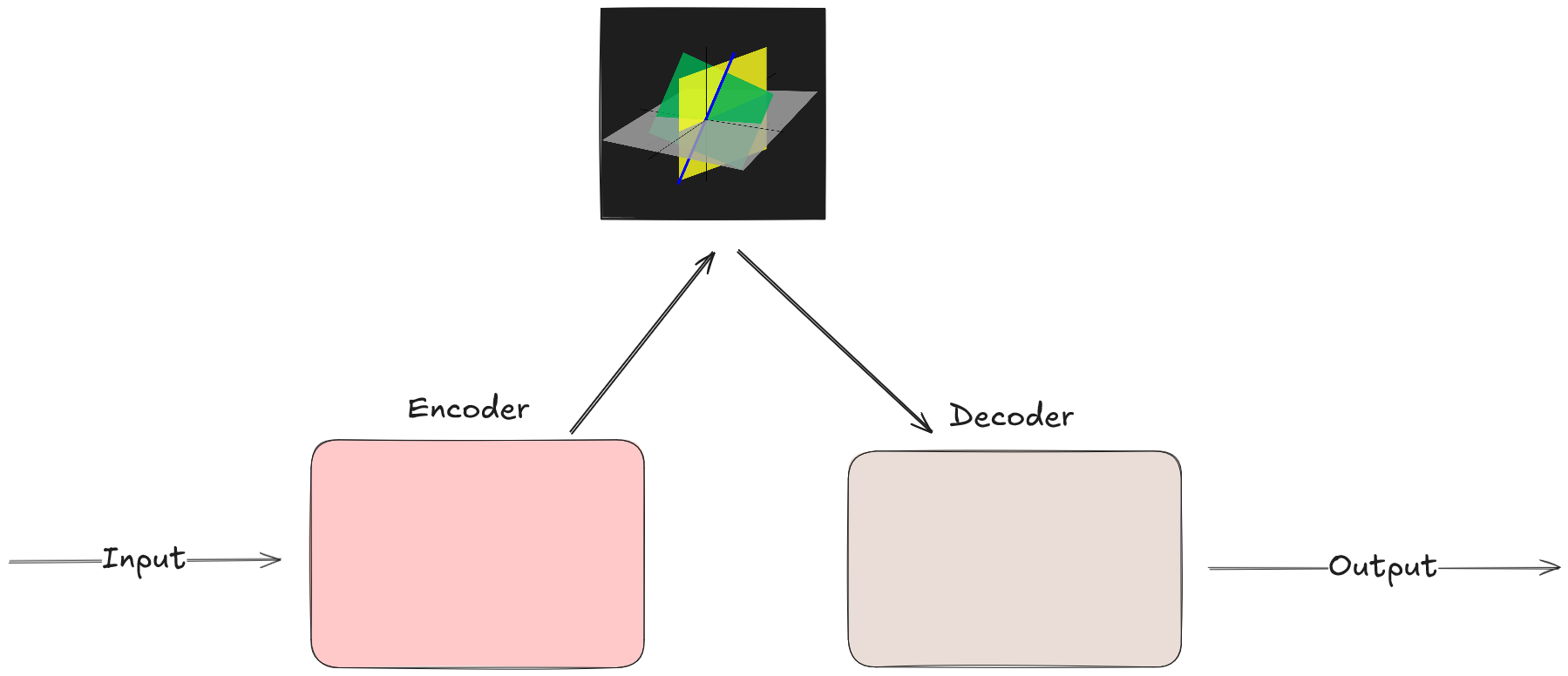
Questi due componenti hanno in comune lo spazio n-dimensionale, nel senso che entrambi utilizzano le informazioni presenti in quello stesso spazio.
Ma cosa c’entra con i transformer?
Transformer: definizione
I transformer sono un approccio simile ma diverso dalle reti Seq2seq.
Una parte cruciale dell’architettura dei transformer è infatti il meccanismo di attenzione, che consente al modello di identificare quali parti di una sequenza di input sono più rilevanti per generare un output significativo.
Così come vale per il funzionamento del cervello, quando abbiamo bisogno di estrarre delle informazioni da un articolo o da un libro, ci concentriamo sull’identificare le informazioni più importanti, per ridurre quelle che invece sono superflue. Leggiamo quanto scritto in grassetto, quali le parti utili rispetto alla nostra ricerca.
In maniera analoga, il meccanismo di attenzione ha il compito di riconoscere la semantica di una frase fornendo al decoder le informazioni più importanti sotto forma di keywords. Per ogni parola, l’encoder decide quali sono le parole più importanti e assegna loro un peso.
Come funziona un transformer
Immagina che invece di scrivere solo la traduzione della frase in una certa lingua, l’encoder definisca anche le parole chiave che sono importanti per la semantica della frase e le dia al decoder insieme alla traduzione “normale”. Queste nuove parole chiave rendono la traduzione molto più semplice per il decoder perché sa quali parti della frase sono importanti e quali termini chiave forniscono contesto alla frase.
In altre parole, per ogni input che l’encoder legge, il meccanismo di attenzione prende in considerazione diversi altri input contemporaneamente e decide quali sono importanti attribuendo pesi diversi a quegli input.
Il decoder prenderà quindi come input la frase codificata e i pesi forniti dal meccanismo di attenzione.
I transformer sono dei modelli che trasformano una sequenza in un’altra con l’aiuto dei consueti encoder e decoder, ma differiscono dai modelli Seq2seq precedentemente descritti perché non implicano alcuna Recurrent Network, ma usano il meccanismo di attenzione per migliorare i risultati nei compiti di traduzione e in altri compiti!
Architettura di un transformer
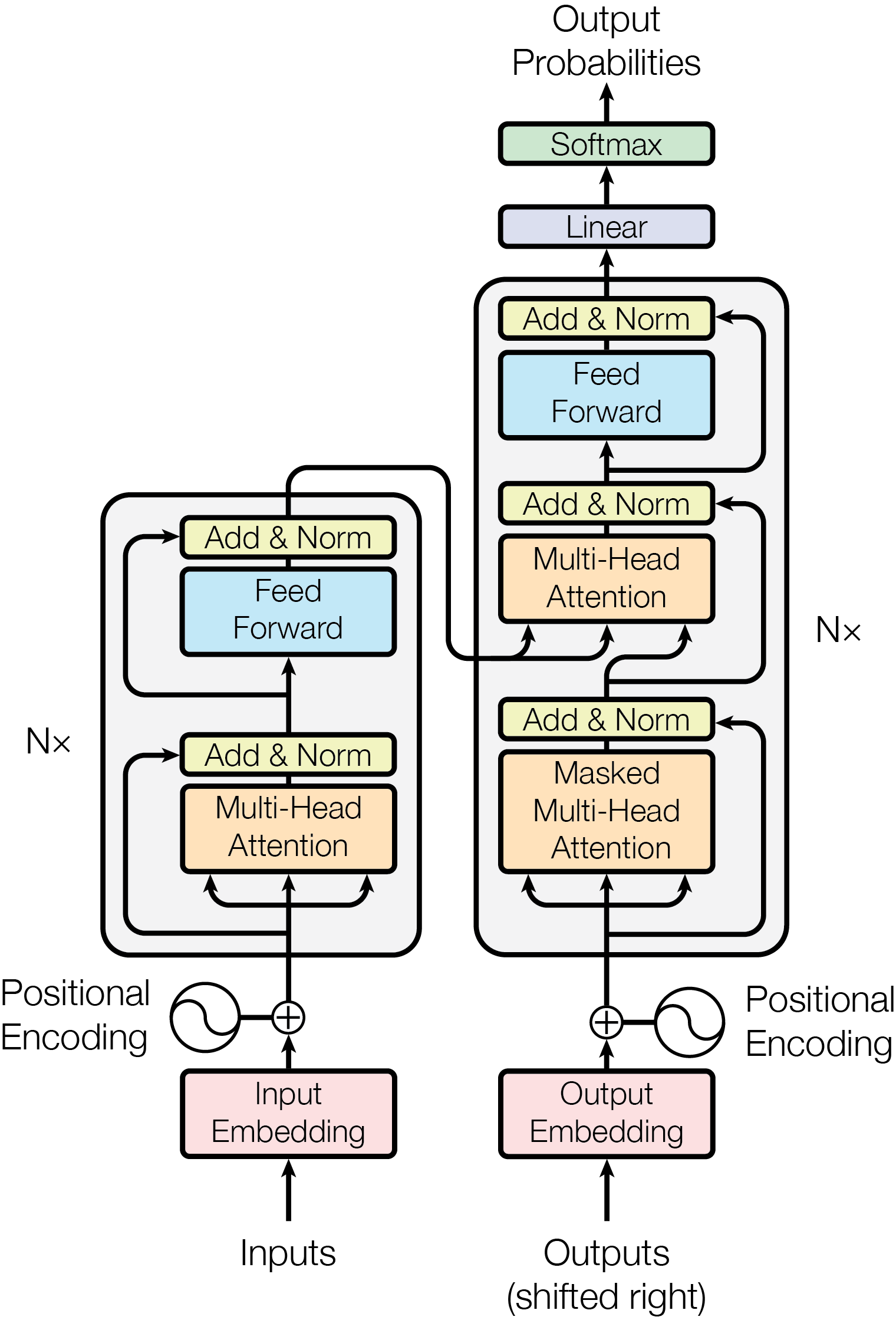
Architettura di un Transformer - Fonte: https://doi.org/10.48550/arXiv.1706.03762
L’encoder è sulla sinistra e il decoder sulla destra. Sia l’encoder che il decoder sono composti da moduli che possono essere impilati uno sopra l’altro più volte, come vediamo grazie agli Nx accanto ai vari blocchi.
Questi moduli sono costituiti principalmente da strati Multi-Head Attention e Feed Forward, mentre gli input e gli output vengono prima incorporati in uno spazio n-dimensionale poiché non possiamo usare direttamente le stringhe, ma queste devono essere convertite in numeri, vettori, matrici, qualcosa che il computer possa “masticare”.
L’idea alla base degli embedding di parole è che quelle relazionate tra loro dovrebbero apparire vicine in un spazio vettoriale, mentre parole non correlate tra loro dovrebbero apparire lontane.
Una parte minima ma importante del modello è la codifica posizionale delle diverse parole. Poiché non abbiamo reti ricorrenti in grado di ricordare come le sequenze vengono inserite in un modello, dobbiamo in qualche modo dare a ogni parola/parte nella nostra sequenza una posizione relativa poiché una sequenza dipende dall’ordine dei suoi elementi. Queste posizioni vengono aggiunte alla rappresentazione incorporata (vettore n-dimensionale) di ogni parola. L’encoding posizionale aggiunge agli embedding testuali informazioni riguardo la posizione del token nell’input.
Abbiamo poi il blocco di attenzione che ha come compito quindi quello di selezionare le parti importanti di una frase, in base al suo significato e al suo contesto, e quindi andrà a creare in output un vettore di attenzione per ogni parola all’interno della frase.
Ogni vettore passa parallelamente nel blocco feed-forward, una delle più semplici messe a punto dei modelli di rete neurale: il funzionamento prevede che ogni input e ogni output seguano la stessa direzione, per cui non ci sono propagazioni dei pesi o degli errori nei nodi precedenti, né cicli di alcun tipo. Questo blocco è essenziale per trasformare l’output del meccanismo di attenzione in una matrice di informazioni facilmente comprensibile per l’unità di decodifica.
Infine, esiste il blocco “Add & Norm”, un componente cruciale dell’architettura dei transformer, costituito da due elementi principali:
- Connessione residua: questo componente consente all’input di bypassare il livello corrente nella rete neurale e di essere aggiunto direttamente all’output di tale livello, ed è una delle soluzioni relative al problema della scomparsa del gradiente. Ciò aiuta a mantenere il flusso di pesi dei gradienti “stabile” durante la backpropagation, essenziale per l’addestramento di reti neurali.
- Normalizzazione dei livelli: la normalizzazione sfrutta i dati a disposizione per “standardizzare” i dati; in altre parole, si parla di normalizzazione quando gli input vengono sommati ai neuroni all’interno di uno strato nascosto. Questa fase di normalizzazione migliora le prestazioni del modello e la velocità di convergenza.

Articoli Correlati