Ottimizzare le query in SQL Server

Query performanti e prestanti sono di fondamentale importanza per il successo di qualsiasi applicazione. Quali sono delle best practices o strumenti da utilizzare per analizzare le prestazioni delle query ed, eventualmente, correggerle?
In questo articolo, analizziamo in che modo ottimizzare le query di SQL Server e come ottenere il massimo dalle prestazioni di questo database.
Definizione di ottimizzazione
Spesso, una query può essere migliorata attraverso molti mezzi diversi, ognuno dei quali ha un costo di tempo e risorse associato.
Ma che cos’è “ottimale”? La risposta a questa domanda determinerà anche quando avremo finito il problema con cui dobbiamo scontrarci per poter passare al passo successivo.
Per semplicità, definiremo “ottimale” come il punto in cui una query funziona in modo accettabile e continuerà a farlo per un ragionevole periodo di tempo in futuro.
Questo ci fornisce diversi spunti di riflessione utili che ci permettono di rivalutare i nostri progressi mentre ottimizziamo:
- La query ora funziona in modo adeguato rispetto alle nostre esigenze?
- Le risorse necessarie per ottimizzare ulteriormente hanno un costo alto?
- Esistono delle query con rendimenti decrescenti per qualsiasi ulteriore ottimizzazione?
- Qual è lo scopo della query e quale dovrebbe essere il risultato?
Prepararci a queste domande ci permette di valutare l’impatto della query e della sua esecuzione: eseguire una query che riporta un milione di record non è di certo ottimale, a meno che non sia strettamente necessario; la frequenza con la quale la query viene eseguita rappresenta un altro parametro di valutazione, così come eventuali parametri i cui input possono avere dei valori “insoliti” o inattesi.
Un buon punto di riferimento per riprendere anche la definizione di una query “ottimale” è chiedersi quanto la query debba essere responsiva o veloce perché gli utenti che usufruiranno di quelle informazioni siano felici del risultato e dei tempi in cui lo hanno ottenuto.
Alcuni strumenti sono a disposizione di SQL Server Workbench, altri richiedono qualche accortezza in più.
Attenzione: parlando di “ottimizzazione”, si intende un risultato migliore di quello attuale. Il risultato perfetto non esiste, in quanto tutto ciò che viene descritto è basato su euristiche che non garantiscono -nè possono garantire- IL risultato migliore per le query che andremo a scrivere. L’assunto di base è: avendo due query equivalenti, ossia i cui risultati sono identici e possono quindi essere sostituite l’una con l’altra, si cerca di individuare quella con il costo inferiore.
Piani di esecuzione
Un piano di esecuzione, nelle basi di dati, è un percorso in uno specifico albero, in cui i nodi non sono gli operatori dell’algebra relazionale, ma gli operatori di scansione, ordinamento e prodotto cartesiano; un piano è una specifica concreta di una possibile esecuzione.
Ci possono essere tanti possibili piani di esecuzione di un’interrogazione; grazie a SQL Server Management Studio, è possibile mostrare in che modo una query viene eseguita mostrando il suo piano di esecuzione.
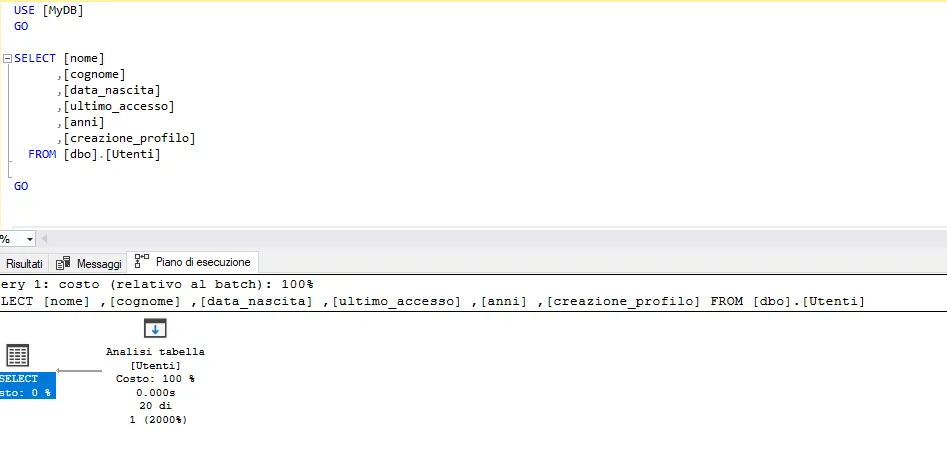
Come visualizzarlo in SQL Server Management Studio?
Al termine della query, nel riquadro dei risultati dovrebbe apparire una scheda aggiuntiva intitolata “Piano di esecuzione”. Se hai eseguito molte query, potresti vedere molti piani visualizzati in questa scheda.
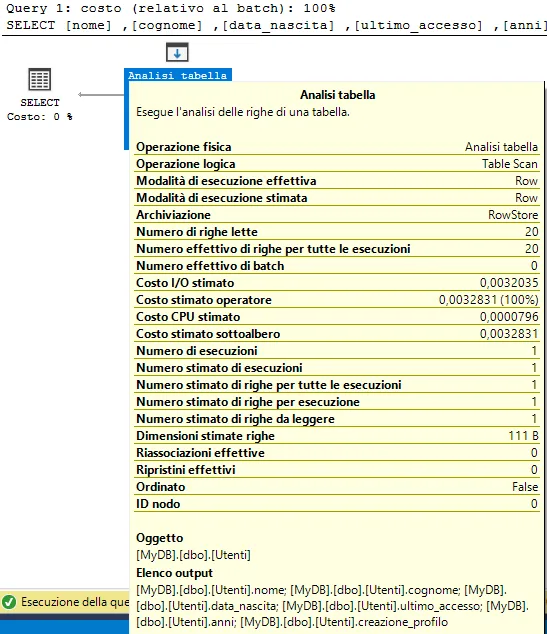
Il piano di esecuzione ci mostra quali tabelle sono state accedute, come sono state accedute, come sono state raggruppate e/o unite e tutte le altre operazioni che si sono verificate lungo il percorso verso il risultato finale.
Sono inclusi i costi delle query, che sono stime della spesa complessiva di qualsiasi componente della query. È incluso anche un livello di dettaglio molto alto come la dimensione dell’insieme finale, il costo della CPU, il costo di I/O e i dettagli su quali indici sono stati utilizzati.
Per ognuno degli step di esecuzione, possiamo valutare quale fase della nostra query ha un costo rilevante e può essere candidata all’ottimizzazione.
In generale, ciò che stiamo cercando sono scenari in cui un numero elevato di righe viene elaborato da una determinata perazione all’interno del piano di esecuzione. Una volta trovato un componente ad alto costo, possiamo ingrandire la causa e come risolverla.
Statistiche
Esiste un’opzione che permette di vedere quante letture logiche e fisiche vengono eseguite quando viene eseguita una query e possono essere attivate in modo interattivo in SQL Server Management Studio eseguendo la seguente query:
SET STATISTICS IO ON;
Le letture logiche ci dicono quante letture sono state fatte dalla cache del buffer. Questo è il numero a cui faremo riferimento ogni volta che parliamo di quante letture è responsabile di una query o di quanto IO sta causando.
Le letture fisiche ci dicono quanti dati sono stati letti da un dispositivo di archiviazione poiché non erano ancora presenti in memoria.
Questa può essere un’utile indicazione di problemi di cache del buffer/capacità di memoria se i dati vengono letti molto frequentemente dai dispositivi di archiviazione, piuttosto che dalla memoria.
Indici
Di base, è possibile accedere ai dati da un indice tramite una scansione o una ricerca (in inglese, seek. Una ricerca è una selezione mirata di righe dalla tabella basata su un filtro (in genere) stretto.
Una scansione è quando viene valutato un intero indice per restituire i dati richiesti.
Se una tabella contiene un milione di righe, una scansione dovrà attraversare tutti i milioni di righe per soddisfare la query.
Una ricerca all’interno della stessa tabella può attraversare rapidamente l’albero binario dell’indice per restituire solo i dati necessari, senza la necessità di ispezionare l’intera tabella.
Se esiste un’esigenza legittima di restituire una grande quantità di dati da una tabella, una scansione dell’indice potrebbe essere l’operazione corretta.
Se abbiamo bisogno di restituire 950.000 righe da una tabella di milioni di righe, allora una scansione dell’indice ha senso. Se dobbiamo restituire solo 10 righe, una ricerca sarebbe molto più efficiente.
Per fortuna, le scansioni dell’indice sono facili da individuare nei piani di esecuzion, perché sono quelle che consumeranno più risorse nell’esecuzione della query.
JOIN e WHERE
L’euristica fondamentale è eseguire selezioni (istruzioni SELECT con WHERE) e proiezioni (SELECT di alcuni attributi di una tabella) il più presto possibile, al fine di ridurre le dimensioni dei risultati intermedi.
Quando eseguiamo una query l’ordine con cui una query viene eseguita, è quella che riguarda le istruzioni chiave. Presa come esempio una query come la seguente:
SELECT city.city_name AS "City"
FROM citizen
JOIN city
ON citizen.city_id = city.city_id
WHERE city.city_name != 'San Bruno'
GROUP BY city.city_name
HAVING COUNT(*) >= 2
ORDER BY city.city_name ASC
LIMIT 2
l’ordine sarà il seguente:
- FROM, JOIN - recupero i dati
- WHERE - filtro i dati
- GROUP BY - aggregazione
- HAVING - filtro i dati ulteriormente
- SELECT - seleziono i dati
- ORDER BY - ordinamento
Questo vuol dire che tutto ciò che viene espresso nella JOIN viene valutato prima di qualsiasi altra clausola; anche se l’insieme restituito fosse di dimensione ridotta, l’uso di una JOIN errata richiederebbe comunque l’intera scansione delle righe di ogni tabella prima di poter valutare quali si adattano alle condizioni espresse nella query.
Un primo trucco consiste dunque nel valutare estremamente bene il tipo di JOIN da eseguire -devo valutare la presenza di valori nulli?- e poi, grazie all’istruzione WHERE, una scrematura quanto più precisa possibile dei dati che voglio ottenere.
Essendo infatti la seconda istruzione che viene valutata, riuscire a tagliare il numero di record che verranno esaminati può apportare un beneficio non indifferente!
AND e OR
SQL Server può filtrare in modo efficiente un set di dati usando gli indici tramite la clausola WHERE o qualsiasi combinazione di filtri separati da un operatore AND. Essendo un operatore esclusivo, queste operazioni prendono i dati e li suddividono in pezzi progressivamente più piccoli, fino a quando rimane solo il nostro set di risultati.
OR è una storia diversa. Poiché è un operatore inclusivo, SQL Server non può elaborarlo in una singola operazione. Invece, ogni componente dell’OR deve essere valutato in modo indipendente. Al termine di questa costosa operazione, i risultati possono essere concatenati e restituiti normalmente.
Lo scenario in cui OR ha prestazioni peggiori è quando sono coinvolte più colonne o tabelle. Non solo abbiamo bisogno di valutare ogni componente della clausola OR, ma dobbiamo seguire quel percorso attraverso gli altri filtri e tabelle all’interno della query. Anche se sono coinvolte solo poche tabelle o colonne, le prestazioni possono diventare sbalorditive.
Un suggerimento utile in questo caso per gestire un OR è eliminarlo (se possibile) o suddividerlo in query più piccole. Suddividere una query breve e semplice in una query più lunga e più lunga potrebbe non sembrare elegante, ma quando si tratta di problemi di prestazioni, spesso è la scelta migliore.





