Fondamenti di Confidential Computing

Ogni giorno, una quantità enorme di dati attraversa reti, server e dispositivi. Proteggerli è una sfida costante. La crittografia nasce proprio per questo scopo e attraverso la codifica delle informazioni, rende i dati illeggibili a chi non possiede le chiavi d’accesso. Questa tecnica tutela i dati da accessi non autorizzati, alterazioni o perdite, garantendone la riservatezza e l’integrità.
Lo stato dei dati
Nel mondo IT, i dati possono trovarsi in tre stati: a riposo, in transito e in uso. I dati archiviati sono detti “a riposo”, quelli che attraversano la rete sono considerati “in transito”, mentre i dati durante l’elaborazione sono “in uso”.

Tradizionalmente, i due momenti chiave in cui i dati vengono protetti sono: a riposo, tramite cifratura dello storage, ed in transito, mediante protocolli sicuri come TLS e HTTPS. Tuttavia, quando i dati vengono elaborati in memoria, diventano temporaneamente visibili a sistema operativo, hypervisor o amministratori. È proprio in questa fase che si concentra il rischio maggiore di accesso o manipolazione non autorizzata. Questo rischio è particolarmente elevato in qualsiasi ambiente condiviso o non completamente fidato (data center, cloud, ambienti multi-tenant).
Nasce il Confidential Computing
Per indirizzare il problema, negli ultimi anni è nato il paradigma del Confidential Computing, formalizzato dal Confidential Computing Consortium (CCC) nel 2019 di proprietà della Linux Foundation. L’obiettivo è proprio quello di proteggere i dati durante l’elaborazione, estendendo la confidenzialità anche allo stato “in uso”. In altre parole, garantire che nessuna entità esterna, nemmeno il cloud provider o un amministratore di sistema, possa accedere alle informazioni mentre vengono processate.
📖 Definizione:
Il Confidential Computing è una tecnologia che protegge i dati durante il loro utilizzo eseguendone l’elaborazione all’interno di un ambiente di esecuzione sicuro basato su hardware.
Come funziona
Il Confidential Computing si basa sui Trusted Execution Environments (TEE), ovvero ambienti di esecuzione isolati e sicuri all’interno del processore, creati e gestiti a livello hardware.
In parole più semplici, un TEE costituisce una “zona protetta” del processore o della memoria, in cui le informazioni restano cifrate e inaccessibili al resto del sistema, compreso il sistema operativo, l’hypervisor o altri processi privilegiati.
A differenza delle normali sandbox o dei container, il TEE non dipende dal sistema operativo o dall’hypervisor, la protezione è implementata direttamente nel silicio del processore. Questo riduce drasticamente la superficie d’attacco e consente di creare un perimetro sicuro che si estende fino all’hardware.
Integrazione con le applicazioni
Quando un’applicazione viene eseguita all’interno di un TEE, i dati sensibili vengono caricati in memoria cifrata e decrittati solo all’interno dell’ambiente protetto. Tutte le operazioni di calcolo avvengono in questa area isolata. Anche se un attaccante compromettesse il sistema operativo o l’hypervisor, non potrebbe accedere ai dati o al codice all’interno del TEE, poiché la memoria è cifrata e le chiavi non sono mai esposte. Allo stesso modo, gli amministratori di sistema, anche se dovessero fare un dump della memoria durante l’esecuzione di un programma che gira all’interno del TEE, non riuscirebbero ad accedere ai dati sensibili.
📌 Curiosità:
Le chiavi di cifratura sono generate e gestite dall’hardware, si trovano in dei registri protetti del processore e non sono mai visibili al software esterno. Vengono utilizzate esclusivamente dal processore per cifrare o decifrare i dati in tempo reale.
L’utilizzo dei TEE da parte delle applicazioni non è automatico: le applicazioni devono essere progettate o adattate in modo da poter operare all’interno dell’ambiente fidato.
❗ Attenzione:
Per sfruttare i TEE, è necessario utilizzare SDK specifici forniti dai produttori di hardware (Intel, AMD) o dalle piattaforme cloud (Azure, Google Cloud, AWS).
In genere, le applicazioni devono essere suddivise in due parti logiche:
- una “trusted” chiamata Enclave, che gira all’interno del TEE e gestisce dati sensibili e operazioni critiche;
- una “untrusted” chiamata Host, che interagisce con l’esterno (sistema operativo, rete, storage) ma non accede mai direttamente ai dati protetti.
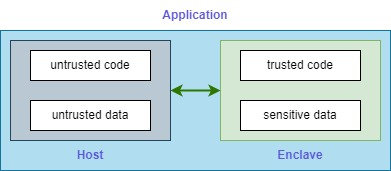
Architettura Applicativa
Attestazione e catena di fiducia
Un elemento essenziale del funzionamento del TEE è l’attestazione. L’attestazione è un processo crittografico che consente a una parte esterna — ad esempio un servizio cloud o un cliente — di verificare l’integrità e l’autenticità dell’ambiente prima di inviare dati sensibili o segreti. In sostanza, il TEE produce un “report di attestazione” firmato dall’hardware, che include informazioni sull’identità del codice, la configurazione del sistema e lo stato di sicurezza.
Questo meccanismo di verifica crea una catena di fiducia (chain of trust), che parte dal processore ed arriva fino al software applicativo.
Casi d’uso
Adesso che sappiamo a grandi linee come funziona, vediamo quali sono le applicazioni di questa tecnologia. Tra i vari possibili scenari di utilizzo e casi d’uso del Confidential Computing, i più rilevanti e sponsorizzati dal consorzio sono:
- MPC (Multi-Party Computation): Esecuzione di calcoli su dati condivisi tra più parti senza rivelarne il contenuto.
- IP (Intellectual Property): Protezione del codice sorgente e degli algoritmi proprietari.
- Insider Threats: Mitigazione dei rischi derivanti da dipendenti o amministratori malintenzionati.
Per comprendere l’importanza della protezione della proprietà intellettuale (IP), provate ad immedesimarvi in una casa farmaceutica che sviluppa un nuovo farmaco. La formula chimica e gli algoritmi di simulazione sono proprietà intellettuali estremamente sensibili, che devono essere protette da spionaggio industriale e furto di dati. Allo stesso tempo però l’azienda ha bisogno sia di eseguire simulazioni complesse su infrastrutture cloud scalabili che non possono essere gestite internamente, sia di collaborare con partner esterni per la ricerca e sviluppo del farmaco. Utilizzando il Confidential Computing, l’azienda può eseguire le simulazioni in un ambiente sicuro, garantendo che nessuno, nemmeno il cloud provider, gli amministratori di sistema o i partner esterni, possano accedere alle informazioni riservate.
Un altro esempio interessante riguardante il Multi-Party Computation (MPC) e sempre legato al mondo della sanità è quello in cui un gruppo di strutture sanitarie o centri di ricerca decidono di collaborare per addestrare un modello di Machine Learning in grado di individuare nuovi farmaci, effetti collaterali o interazioni molecolari.
Ogni struttura (ospedale, laboratorio, università) possiede dataset sanitari privati e sensibili, cartelle cliniche, dati genetici, risultati di test, ecc. Per legge e per etica, nessuno può condividere questi dati in chiaro con altri enti né con il cloud provider. Ed è qui che entra in gioco il Confidential Computing.
Prima che i dati vengano trasferiti, ciascuna struttura effettua un meccanismo di attestation verso l’ambiente di Confidential Computing, per verificare che l’ambiente sia sicuro e conforme alle policy previste. Solo dopo questa verifica, i dati delle due strutture vengono caricati in memoria (in forma cifrata) all’interno del TEE, dove il modello viene addestrato. Durante tutto il processo, né le strutture partecipanti né il cloud provider possono accedere ai dati. L’output è un modello risultante dalla fusione delle informazioni elaborate all’interno del TEE.
Risultato: tutti contribuiscono al training del modello, tutti ne beneficiano, ma nessuno vede i dati altrui.
Conclusioni
- Il Confidential Computing rappresenta un passo avanti significativo nella protezione dei dati sensibili, estendendo la sicurezza dei dati anche durante l’elaborazione.
- Questo paradigma apre nuove opportunità per la collaborazione sicura, l’elaborazione di dati sensibili e la protezione della proprietà intellettuale, rendendolo una tecnologia chiave per il futuro.
- La transizione verso il Confidential Computing non è semplice e richiede un cambiamento sia a livello di infrastruttura che di sviluppo applicativo.
Nella seconda parte di questo articolo, vedremo come creare una Virtual Machine con tecnologia Intel SGX in ambiente Cloud (Azure) in grado di sfruttare il Confidential Computing.



